Best AI Models for DevOps & SRE: Real-World Agent Testing
You’re a software engineer. Maybe you’re doing DevOps, SRE, platform engineering, or infrastructure work. You’re using large language models, or at least you should be. But which ones? How do you know which model to pick?
I was in the same situation. I made choices based on gut feelings, benchmark scores that didn’t mean anything in production, and marketing claims. I thought I should change that.
So I ran ten models from Google, Anthropic, OpenAI, xAI, DeepSeek, and Mistral through real agent workflows. Kubernetes operations. Cluster analysis. Policy generation. Systematic troubleshooting. Production scenarios with actual timeout constraints. And the results were shocking compared to what benchmarks and marketing promised.
Seventy percent of models couldn’t finish their work in reasonable time. A model that costs 120 dollars per million output tokens failed more evaluations than it passed. Premium “reasoning” models timed out on tasks that cheaper models handled easily. Models everyone’s talking about couldn’t deliver reliable results. And the cheapest model? It delivered better value than options costing twenty times more.
By the end of this article, you’ll know exactly which models actually work for engineering and operations tasks, which ones are unreliable, which ones burn your money without delivering results, and which ones can’t do what they’re supposed to do.
How I Compare Large Language Models
In this article, I’m comparing large language models - LLMs - from Google, Anthropic, OpenAI, xAI, Deepseek, and Mistral. Some of these companies have multiple models in the comparison, so we’ll see how different versions stack up against each other.
Now, you might be wondering why I’m creating my own comparison instead of just relying on existing benchmarks.
The primary reason is simple: I need to know which models work best for the agents I’m building.
But there’s a secondary reason that’s probably more important. I want to truly know which model performs better and under which conditions. This can’t be based on my feelings or personal experience. It needs to be based on data. We’re engineers, damn it. We’re supposed to make decisions based on data, not how we feel. Well, some of us at least. I also don’t trust the standard benchmarks because models are often trained on them to game the results.
So how am I doing this? I have a set of tests that validate whether my agents work correctly. I run those same tests for each of the models. Since these are actual tests, I know whether the output is acceptable or not. When tests fail, I analyze what went wrong and add that information to the datasets. These datasets include duration, input and output tokens used, the prompts themselves, AI responses, pass or fail status, and so on. All of that data is then injected into prompts that run the actual evaluations and provide scoring.
Now, this approach is different from standard AI evaluations. Most evals have to figure out both whether something worked and how well it worked. Mine doesn’t. The functional tests already determined if the output is acceptable. The evals are scoring how well it worked, with full context about what passed or failed and why. It’s a more grounded approach because the scoring is based on real-world agent performance, not trying to guess if something is correct.
All the models were compared using the same agent based on the Vercel SDK. That means I’m ignoring the differences in performance you’d get from specific agents like Claude Code. Those differences can be huge. That’s not what I’m testing here, though. This comparison is about the models themselves.
As for what I’m actually testing: I’m not measuring code generation directly since that’s more subjective. Instead, all the tests are based on Kubernetes, which is well understood by all these models. I expect the results would be similar for any type of development task, but these specific results are fine-tuned for DevOps, ops, and SRE type of work.
Now, let’s break down exactly what criteria I used to evaluate these models and what scenarios they were tested against.
LLM Evaluation Criteria and Test Scenarios
Now, I believe understanding the criteria and scenarios is important for making sense of the results. But if you’re anxious to see which models won and lost, feel free to skip ahead to the next section with the results. I won’t be offended.
I evaluated these 10 models across five key dimensions. First is overall performance - basically quality scores measuring how well each model handles different types of agent interactions. Second is reliability - can the model actually complete evaluation sessions without crapping out? This is measured by participation rate and completion success. Third is consistency - how predictable is the model’s performance across different tools? You don’t want a model that excels in one area but completely fails in another. Fourth is cost-performance value - your quality score relative to pricing per million tokens. Raw performance doesn’t mean much if it costs 50 times more than alternatives. And fifth is context window efficiency - how well models handle large context loads. Some scenarios send over 200,000 tokens to the models. Having a massive context window doesn’t guarantee good performance if the model can’t actually use it effectively.
Now, timeout constraints are critical here. If a model can’t deliver results in reasonable time, it’s not useful in production. Real-world agent workflows have time budgets - 5 minutes for quick pattern creation, 45 minutes for comprehensive cluster analysis. When I say an evaluation failed, I mean the timeout was exceeded. This isn’t about models working indefinitely - it’s about delivering what we need in reasonable periods.
So let’s look at the five evaluation scenarios. Each one tests different aspects of what makes AI agents actually useful in production environments.
First is Capability Analysis. This is basically an endurance test that puts models through about 100 consecutive AI interactions over a 45-minute period. The goal is to discover and analyze every single Kubernetes resource in the cluster. What makes this challenging is maintaining quality throughout these marathon sessions while demonstrating deep Kubernetes knowledge for each resource type. The question we’re asking is: can the model sustain performance without degrading over extended workflows? This matters because in production, you need models that don’t get sloppy or confused after dozens of interactions. Interestingly, 70% of the models we tested completely failed at this.
Second is Pattern Recognition. This evaluates how well models handle multi-step interactive workflows within a tight 5-minute timeout. The workflow goes like this: expand trigger keywords into comprehensive lists, abstract those specific requirements into reusable organizational patterns, and create templates that get stored in a Vector database. Think of it as capturing your team’s deployment best practices so they can be automatically applied to future deployments. The challenge here is speed combined with abstraction - transforming specific requirements into general patterns quickly. What we’re really testing is how well the model handles rapid, iterative refinement workflows. This matters because in production, you often need quick answers for pattern matching, not deep philosophical analysis.
Third is Policy Compliance. This tests whether models can perform schema-by-schema analysis of cluster resources within a 15-minute timeout. The tasks involve expanding policy triggers into comprehensive resource categories and generating complete, syntactically correct Kyverno policies with CEL validation expressions. This is about proactive governance - integrating security and compliance requirements directly into AI recommendations, rather than blocking manifests after they’re created. The challenge is thoroughness under time pressure. Comprehensive schema analysis can’t be rushed, but you also can’t take forever. The question is: can the model balance depth of analysis with time constraints? Thirty percent of models completely failed this scenario because they didn’t have large enough context windows to handle the schema complexity.
Fourth is Recommendations. This is manifest generation under extreme context pressure within a 20-minute timeout. The context load is brutal - up to 50 large Kubernetes resource schemas, totaling over 100,000 tokens. The process involves transforming user intent into production-ready YAML manifests through targeted clarification questions. What makes this different from generic deployment tutorials is that it needs to understand YOUR specific cluster’s capabilities, YOUR organization’s patterns, and YOUR governance policies. The challenge is processing this massive schema context while maintaining accuracy. The question we’re testing is: how efficiently does the model actually utilize context windows for complex generation? This is where we learned that having a massive context window doesn’t mean the model can use it effectively. Fifty percent of models failed at manifest generation within the timeout constraints.
Fifth and final is Remediation. This one is different from the previous scenarios. The earlier four were one-shot interactions - send a prompt, get a response. Remediation runs as an investigation loop. The model receives the issue description along with a list of tools it can use. It then decides which kubectl commands to run to gather data. The agent executes those commands and adds the output back into the context. The model analyzes the new information and decides whether to request more tool executions or conclude with “here’s the problem and here’s how to solve it.”
The model is completely free in how it investigates. It could decide it has enough information without executing any tools at all, or it could loop up to 30 iterations gathering more and more data. In practice, successful investigations typically run 5 to 8 cycles, all within the timeout constraints for that particular scenario.
What makes this challenging is that the model must conduct intelligent, systematic investigation. Kubernetes failures present symptoms, not causes. A pod that won’t start might actually be failing because of a missing PersistentVolumeClaim or a network policy blocking traffic. The model needs to decide which kubectl commands to run next based on what it learned from previous commands, maintain investigation context throughout all those iterations, understand cross-resource dependencies, and know when it has enough information to provide the actual root cause and remediation steps with proper risk assessment. The performance variance here was extreme - we saw a 42x difference between the fastest and slowest models, ranging from 2.5 seconds to over 22 minutes for the same investigation.
So those are the five scenarios testing different aspects of what makes AI agents useful in production - endurance, speed, thoroughness, context handling, and systematic investigation. Now let’s see how these 10 models actually performed.
AI Model Benchmark Results
Let’s start with what honestly shocked me the most. Seven out of ten models - that’s 70% - couldn’t complete the capability analysis within 45 minutes. They just ran out of time trying to work through those hundred consecutive interactions. Half of the models exceeded timeout constraints for manifest generation. Three out of ten failed at policy compliance because they couldn’t finish the work within the 15-minute window.
Now, this is important to understand. When I say a model failed, I don’t mean it crashed or threw errors. These are timeout failures. The models were still working, still trying to complete the task, but they couldn’t deliver results within reasonable production timeframes. And that’s what matters in real deployments. If your agent takes 2 hours to analyze a cluster when you need answers in 45 minutes, that model isn’t useful to you, no matter how good its eventual output might be.
But some models had truly disastrous reliability issues that go beyond just being slow. GPT-5-Pro was the real shocker here. This model couldn’t complete nearly half of all evaluations - only 52% participation rate. It exceeded timeouts so often that it failed more tests than it passed. Pattern recognition? Zero. Couldn’t finish within the time budget. Recommendations? Also zero.
Now, GPT-5-Pro is supposed to be the advanced version of GPT-5. It’s positioned as the model for complex reasoning tasks. And here’s the thing - these aren’t impossibly hard tasks. We’re talking about Kubernetes operations that production agents need to handle. It’s like having a brilliant mathematician who might excel at complicated algebra but takes hours to answer “what’s two plus two?” Being brilliant doesn’t mean much if you can’t answer straightforward questions relatively quickly.
Then there’s Mistral Large. Now, I expected Mistral might struggle - it’s generally not considered among the absolute top-tier models. I included it anyway because, hell, we need to support European AI development. But the results were rough. This model couldn’t finish remediation investigations at all. Zero score. It would start the investigation loop but couldn’t complete the systematic troubleshooting process within the time constraints. Only 65% participation rate overall, meaning it failed to complete a third of all evaluations.
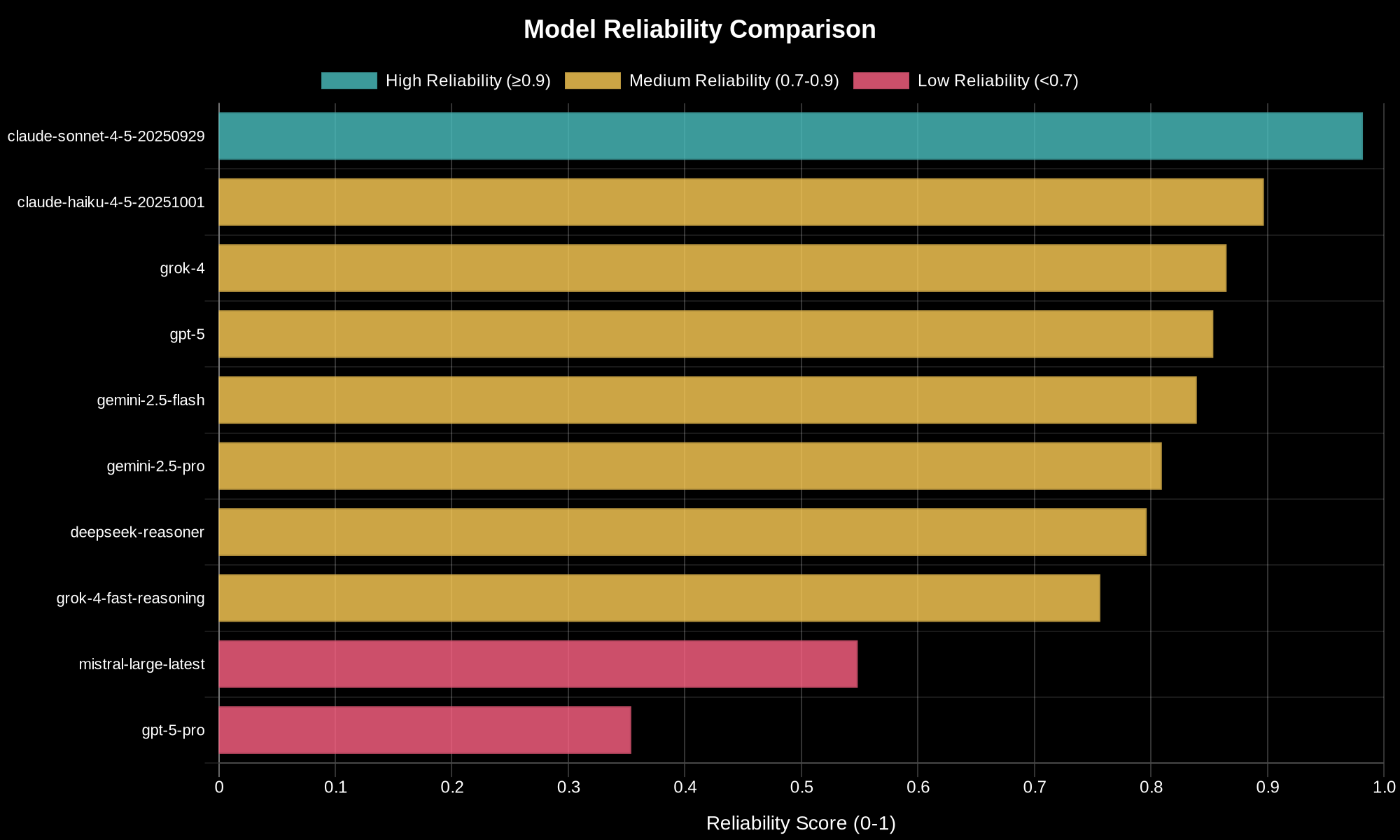
Now let’s talk about cost, because this is where things get interesting. The cheapest model isn’t always the best value, and the most expensive definitely isn’t either.
Grok 4 Fast Reasoning absolutely dominates the cost-performance category. It achieved a value score more than three and a half times better than the next competitor. At 35 cents per million tokens - that’s 20 cents for input, 50 cents for output - it’s the cheapest model in this evaluation.
But here’s the catch. Remember that policy compliance test I mentioned earlier? Grok 4 Fast Reasoning couldn’t complete it within the 15-minute window. It scored around 40%, which is catastrophically low. This makes it production-dangerous for policy generation workflows. So yeah, it’s cheap and fast for most tasks, but you absolutely cannot use it for generating Kyverno policies.
On the other hand, Gemini 2.5 Flash offers a more balanced value proposition. At 30 cents for input and two fifty for output per million tokens, it delivers solid 78% overall performance with no critical failures. It’s about twice as cheap as some premium options while still being production-ready across all scenarios.
Now, about those premium models. Some of them cost anywhere from 8 to 20 times more than budget options. The question is: do they deliver proportional value?
And then there’s GPT-5-Pro. Remember that model that couldn’t complete half its evaluations? The one with zero scores in pattern recognition and recommendations? That one costs almost 68 dollars per million tokens. Fifteen dollars for input, a hundred and twenty dollars for output. It’s so ridiculously expensive compared to everything else that it actually screwed up my cost-versus-quality graph.
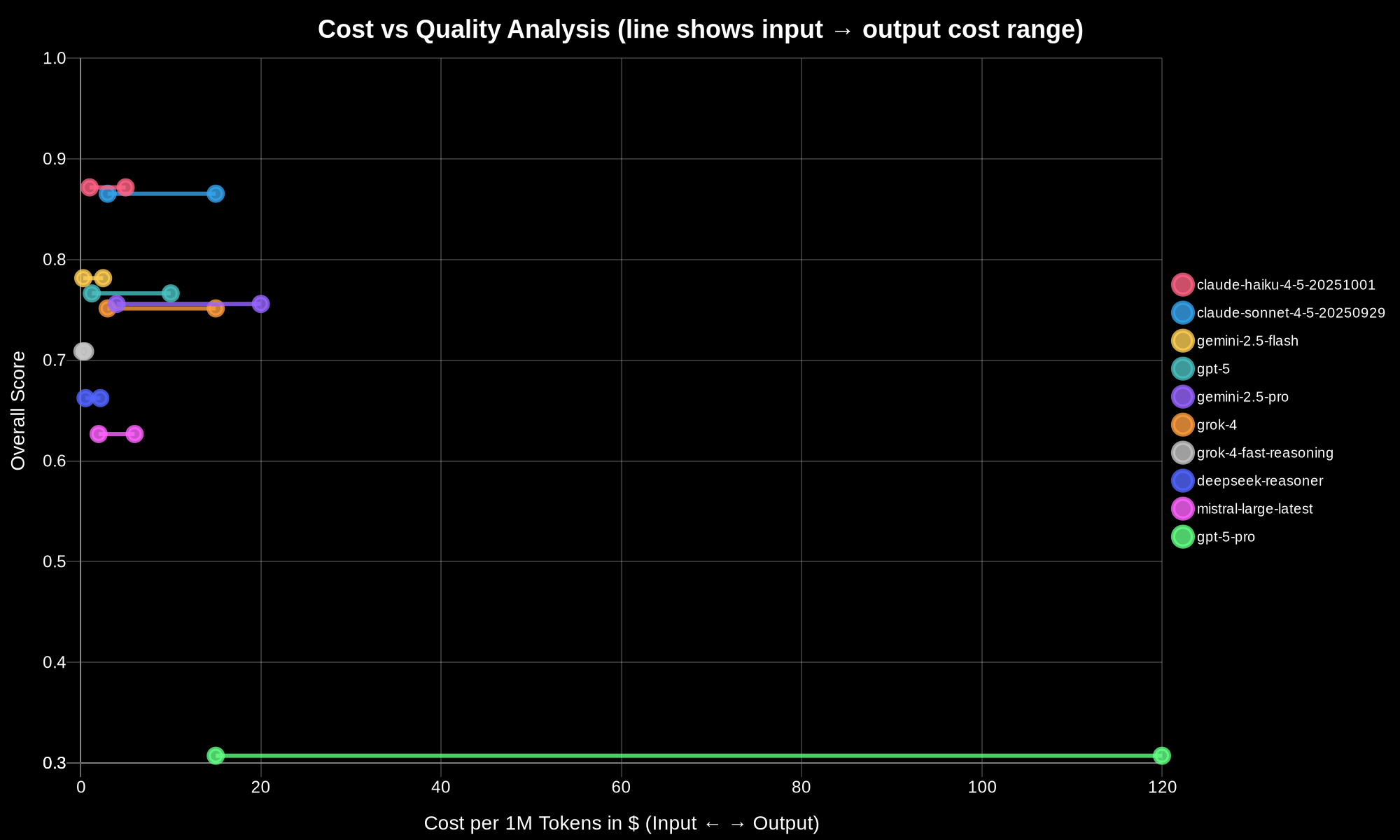
Looking at tool-specific performance reveals something interesting. There’s no universal winner that dominates everything. Instead, we see specialization. Some models excel at certain tasks but struggle with others.
In capability analysis, the performance spread is massive - from 90% at the top down to around 56% at the bottom. That’s a significant difference in how well models handle those hundred consecutive interactions over 45 minutes.
Pattern recognition shows even more dramatic variance. Some models excel at this rapid 5-minute workflow, while others - remember GPT-5-Pro? - scored absolute zero. Couldn’t complete it at all.
Policy compliance ranges from 83% down to 40%. That bottom score is Grok 4 Fast Reasoning failing to complete the comprehensive schema analysis within 15 minutes.
For recommendations, we saw a 42 times speed difference between the fastest and slowest models. Same task, same schemas, wildly different completion times. Some models process those 100,000-plus tokens efficiently, others choke on them.
And remediation shows the widest gap of all - complete failures at zero versus near-perfect scores at 95%. This systematic investigation workflow really separates the capable models from the ones that just can’t handle iterative problem-solving.
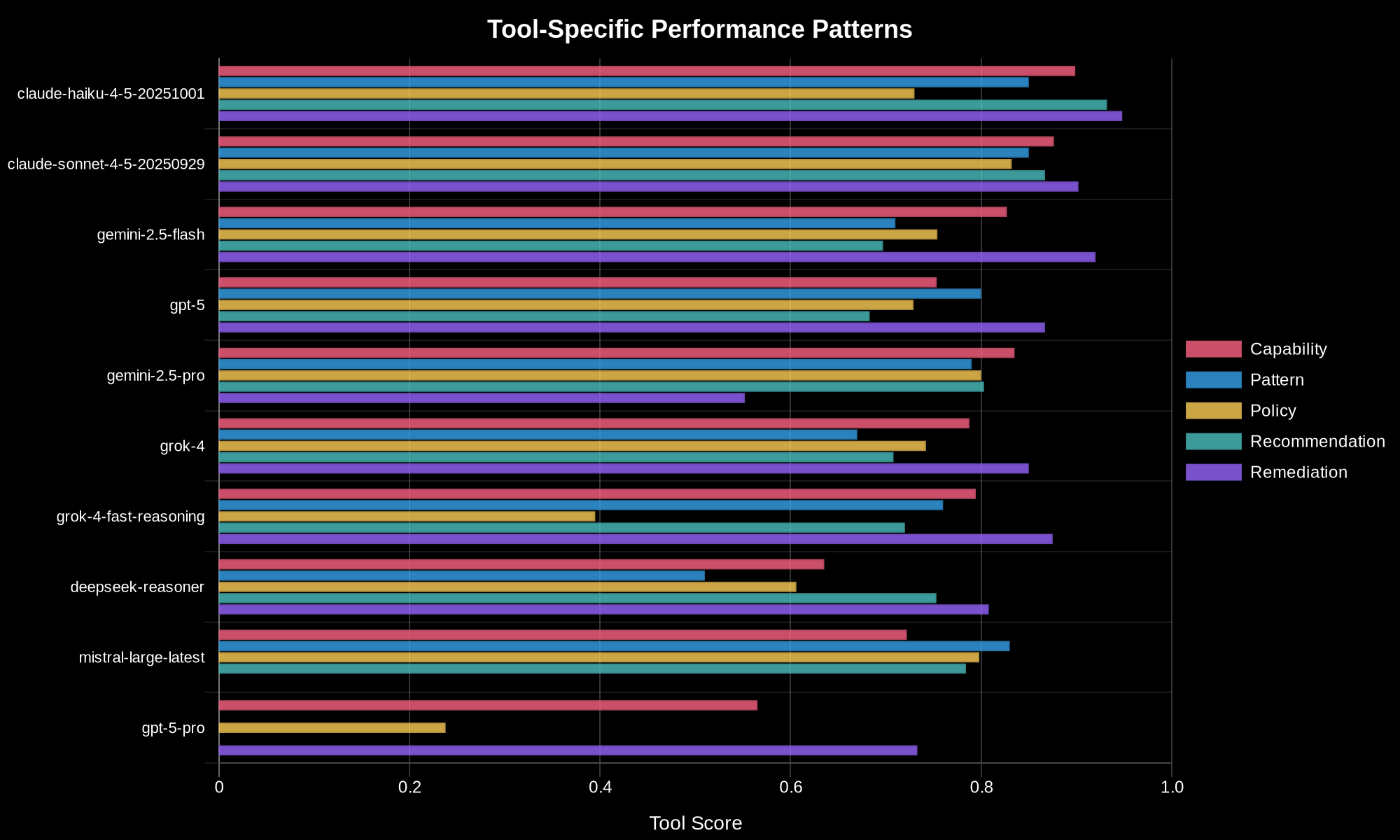
Here’s where things get really interesting. Context window size matters, but efficiency matters even more.
The pattern is clear at first glance. Models with larger context windows generally score higher in recommendations. Makes sense, right? That scenario sends a hundred thousand or more tokens of context in each interaction, including up to 50 large Kubernetes schemas. Bigger window means more room to work.
But then there’s Claude Haiku that completely breaks the pattern. This model has only a 200K context window - yet it scored 93%, the highest score in the entire recommendations category. It’s processing these massive context loads with 50-plus schemas more effectively than models with five times larger windows. That’s not about having more space. That’s about using the space you have more efficiently.
And on the flip side, Grok 4 Fast Reasoning has a massive 2 million token context window but couldn’t complete tasks within the timeout constraints. All that capacity, but it can’t process the information fast enough to matter.
The lesson here is clear: context size alone doesn’t guarantee performance. It’s about how efficiently the model utilizes what it has.
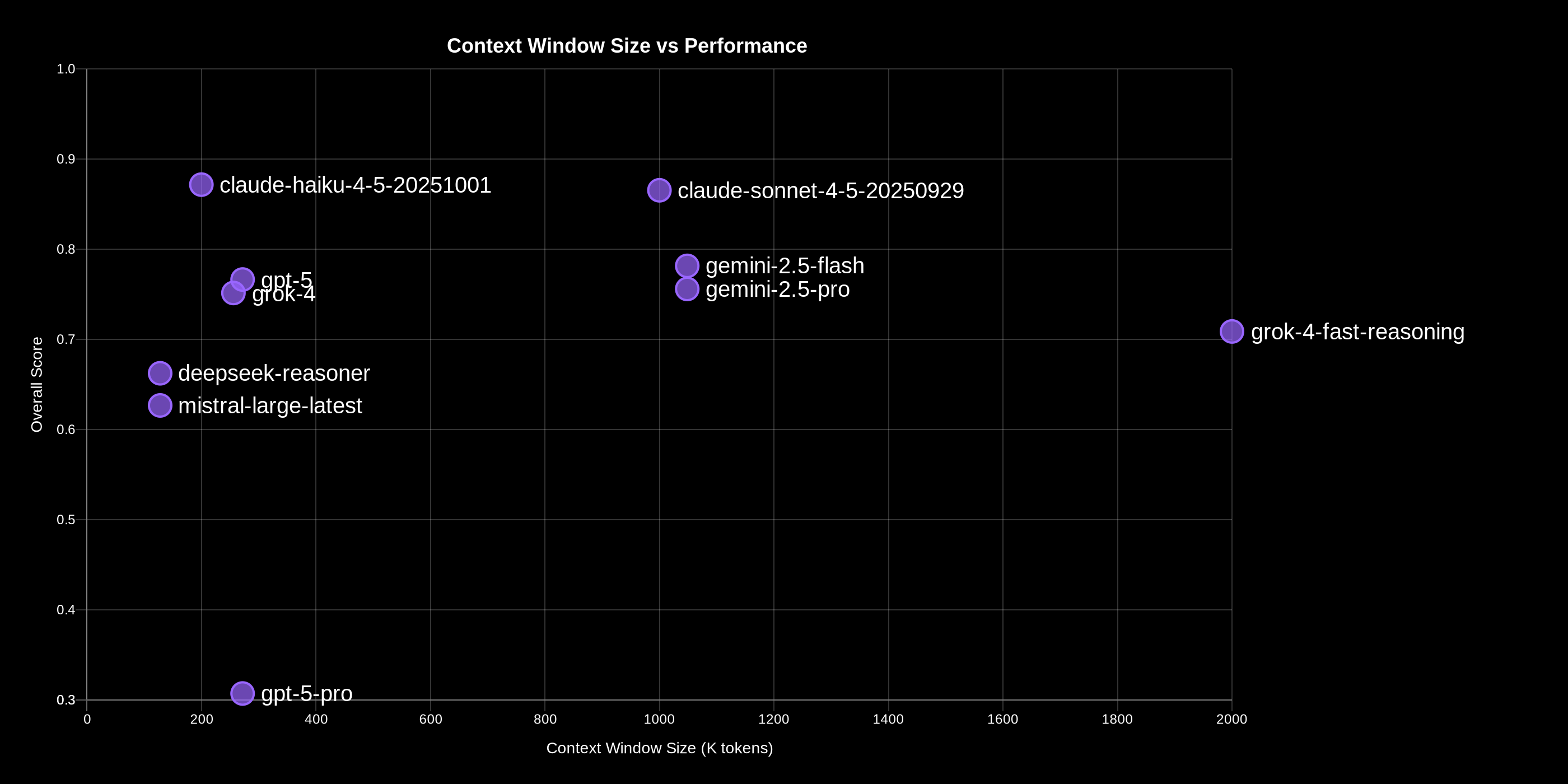
When I synthesized all this data - the reliability issues, cost trade-offs, tool-specific performance, and context efficiency - clear performance tiers emerged. Three distinct categories separated by real performance gaps.
Let’s start at the bottom. The bottom tier includes models scoring below 70% overall or below 80% reliability. Four models landed here.
Now, two of these I expected to struggle. Mistral Large and DeepSeek Reasoner aren’t generally considered top-tier models, so their results weren’t surprising. DeepSeek struggled with pattern recognition and endurance testing, while Mistral couldn’t complete remediation investigations. Not great, but not shocking either.
The real disappointments were GPT-5-Pro and Grok 4 Fast Reasoning. These were supposed to be competitive options, but they failed in ways I didn’t anticipate. The primary issue? They take unreasonably long to analyze tasks, consistently hitting my timeout constraints. GPT-5-Pro couldn’t complete nearly half of all evaluations - that catastrophic 52% participation rate - with zero scores in pattern recognition and recommendations. It’s not that it got the answers wrong. It’s that it couldn’t deliver answers within production timeframes.
And Grok 4 Fast Reasoning - with “fast” literally in its name - has that production-dangerous 40% policy compliance score because it couldn’t complete the comprehensive schema analysis within 15 minutes. The irony of calling it “fast” when it consistently exceeded timeouts isn’t lost on me.
The bottom line: these models have critical failures that make them unsuitable for production use, or at minimum, you need to be very careful about which scenarios you use them for.
Moving up to the mid tier, we have four models that are actually production-ready. They score between 70% and 80% overall with at least 80% reliability. This includes Gemini 2.5 Flash - our balanced value champion at 30 cents input and two fifty output per million tokens. GPT-5 with its solid consistency and pattern recognition. Gemini 2.5 Pro with strong capability analysis despite that weak remediation score. And Grok 4 with good reliability and remediation performance. These are dependable models with some tool-specific weaknesses, but nothing catastrophic. They’ll get the job done, just not at the absolute highest level.
And then we have the top tier. What’s interesting is that the data naturally separated into these groups. There’s a real performance gap between the mid-tier models clustering around 75% to 80% and the top performers. The top tier models consistently score above 85% overall with significantly higher reliability and consistency scores. They’re not just a little better - they’re noticeably better across the board.
Only two models made it here.
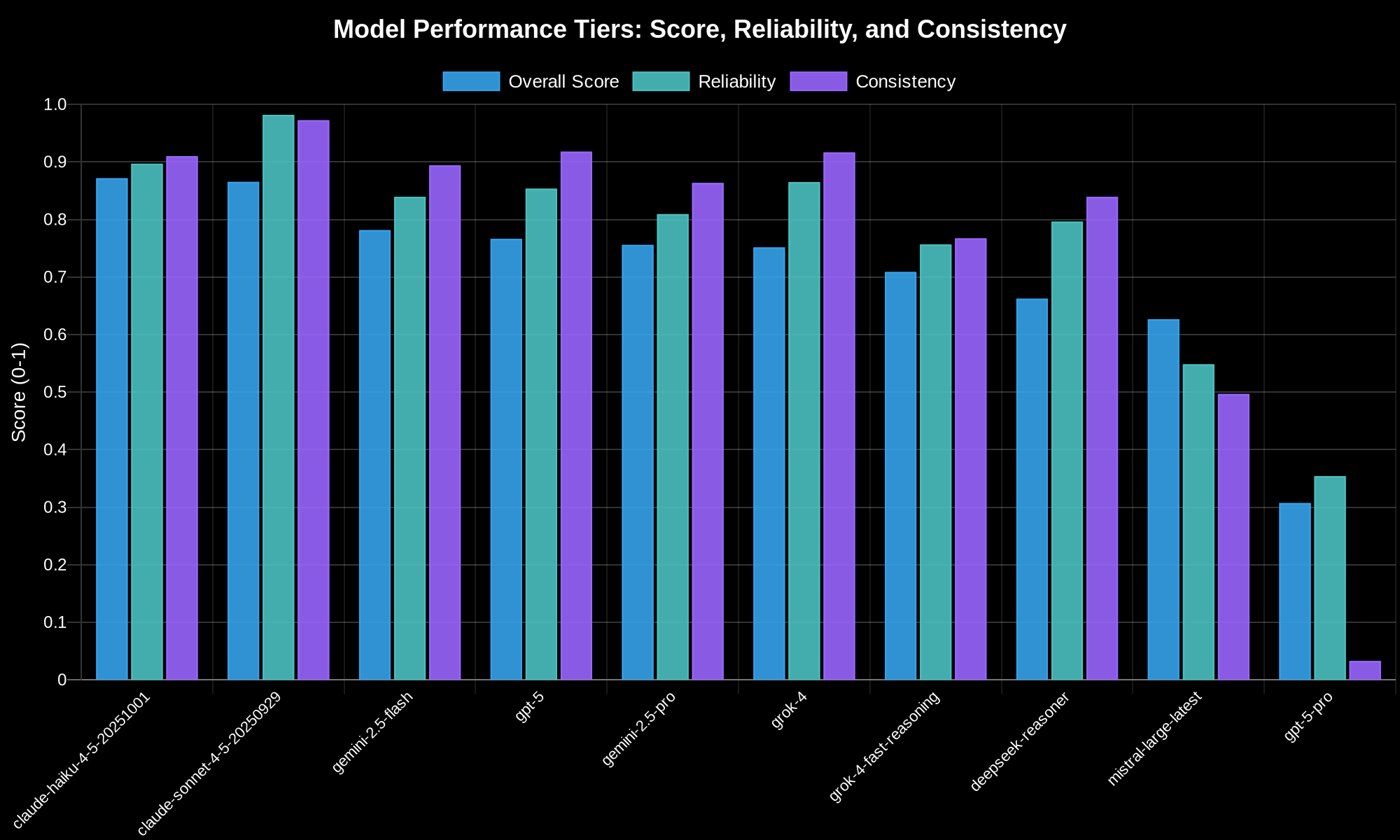
Claude Haiku scored 87% overall - actually the highest overall score in the entire evaluation. It leads in four out of five tool categories: capability analysis, pattern recognition, recommendations, and remediation. This is the model with only a 200K context window that somehow achieved the highest recommendations score - 93%. Its efficiency is remarkable. And it costs $1 input and $5 output per million tokens.
Claude Sonnet also scored 87% overall - slightly lower raw performance than Haiku - but it has the highest reliability and consistency scores in this entire comparison: 98% reliability and 97% consistency. It achieved a 100% participation rate across all evaluations. Never failed to complete a test. Never exceeded timeouts. When you absolutely need your agent to finish what it started, this is your model. But that reliability comes at a premium: $3 input and $15 output per million tokens, three times more expensive than Haiku.
So here’s the trade-off between these two top performers. Haiku gives you the best raw performance across most scenarios at a reasonable price, but with around 90% reliability. Sonnet gives you near-perfect 98% reliability and consistency - it will never fail you - but at three times the cost and with slightly lower performance in most categories. Both are excellent choices. The question is whether you’re optimizing for maximum performance or maximum reliability.
Now, I’ve shown you the data - the failures, the costs, the performance patterns, the tiers. But data alone doesn’t help you make decisions. You need concrete recommendations. Which model should you actually use? Let’s break this down from worst to best, so you know exactly what to avoid and what to adopt.
AI Model Rankings and Recommendations
Before we dive into the rankings, an important caveat. This ranking is specific to ops, DevOps, SRE, and software engineering tasks. Models that scored low here might excel at other types of work like creative writing, general conversation, or completely different domains. Similarly, models that scored high here might not be the best choice for everything. This comparison is focused on agent-based technical workflows. Keep that in mind as we go through the rankings.
10th place: GPT-5-Pro. $15 per million input tokens, $120 per million output tokens. You want me to pay premium prices for a model that can’t finish half the tests? This thing failed more evaluations than it completed. When it does manage to finish something, it takes forever. You want us to pay those prices for this? Hell no.
9th place: Mistral Large. This is marketed as Europe’s answer to OpenAI. Europe’s shot at AI independence. And it can’t even troubleshoot a Kubernetes cluster. Zero in remediation. Failed a third of all tests. Come on, Europe. This is embarrassing.
8th place: DeepSeek Reasoner. The model everyone’s talking about. Trained for pocket change. OpenAI thinks they stole their data. Great benchmark scores. And it can’t handle real agent workflows. Below 70% overall. Turns out you can game benchmarks, but you can’t fake production performance.
7th place: Grok 4 Fast Reasoning. “Fast Reasoning” - except it’s neither fast nor good at reasoning. Exceeded timeouts on complex analysis. 40% on tasks requiring systematic thinking. What’s the point of putting “reasoning” in your name if you can’t reason? Cheapest model at 20 cents input, 50 cents output. You get what you pay for.
Those are the models you should avoid. Now let’s look at the middle of the pack. Models that actually work, but won’t blow your mind.
6th place: Gemini 2.5 Pro. Mid-tier performance. Nothing exciting, nothing terrible. The model you choose when you have no strong opinions. Works fine. Won’t impress anyone.
5th place: Grok 4. Mid-tier. Reliable. Boring. Won’t blow your mind, won’t let you down. Elon’s safe option.
4th place: GPT-5. The normal version, not the expensive disaster. Mid-tier. Consistent. Predictable. The Toyota Camry of AI models. Gets the job done without drama.
Now we’re getting to the good stuff. The top three. Models that actually deliver.
3rd place: Gemini 2.5 Flash. Best value for money. 30 cents input, $2.50 output. 78% overall performance with no catastrophic failures. When your CFO asks why you’re spending money on AI, show them this model. Good performance, reasonable price. Smart choice.
2nd place: Claude Sonnet. $3 input, $15 output. 87% overall. 98% reliability - the highest in this entire comparison. Never failed a single test. When you absolutely cannot afford your agent to crap out, this is your model. Enterprise-grade reliability. Three times more expensive than Haiku. Worth it if failures cost you money.
And now, the winner.
1st place: Claude Haiku. $1 input, $5 output. 87% overall - tied with Sonnet but wins on raw performance. Leads in 4 out of 5 categories. Here’s the kicker: only 200K context window, yet it achieved the highest score for processing massive context loads. That’s not about having more space. That’s about using what you have efficiently. Best price-performance ratio. This is the model to beat. Use this unless you’re not price-conscious and can afford Sonnet’s premium for maximum reliability.
So here’s the bottom line. Start with Claude Haiku for most work. Switch to Claude Sonnet when you need that 98% reliability and can afford the premium. Use Gemini 2.5 Flash when budget matters. And avoid the bottom tier entirely unless you have very specific use cases where their weaknesses don’t matter.
Was this useful? Should I repeat these evaluations every time a new model is released? Which criteria do you think is missing? What should I include in future evaluations when new models appear? Let me know in the comments.
The full report with all the detailed data is available at https://github.com/vfarcic/dot-ai/blob/main/eval/analysis/platform/synthesis-report.md