Mastering Developer Portals: Discover & Integrate API Schemas with Port
I am so dissaspointed with developer portal consoles for ignoring the fact that almost everything is discoverable through APIs. Why should I design forms and fields in Backstage if Backstage should be able to ask an API for a schema? Even if that schema is not exactly what I need and I might have to remove parts of it, that’s still easier and better than starting from scratch. It’s a waste of time to do the same thing over and over again. We should define what we have, expose that through an API, and all other tools should just “discover” it. Just as that’s true for, let’s say, kubectl, it should be true for graphical user interfaces.
Hence, I spent months complaining about it and… I got it.
Port folks answered my call for help and developed just what I need. Port can now discover schemas and create data models and actions.
All I have to do is tell it to synchronize and…
…data models appear automagically.
Not only that, but actions like those to create, update, or delete resources are created as well.
I would need to spend hours translating Kubernetes definitions to Port JSON to create those data models and those actions. Now, I either do not need to do anything or, in some case, I might need to modify them slightly.
This is a game changer and, honestly, I’m surprised that no one, as far as I know, did it before. The ability to discover resource definitions makes a huge difference. It allows me to stop wasting my time rewriting “stuff” from one format to another but focus on creating APIs and let others discover what’s behind them.
The feature I’m about to show is new. It’s unpolished. It is missing quite a few things. Yet, I got so excited when I saw the first iteration of it that I had to jump in, to try it out, and to share it with you. It is so new that you will hear me complain a lot. I’ll be doing that with the best possible intention. The feature I’m about to show you is so new that all my complaints should be seen in the light of exploring something in its infancy so they should not be treated as issues but, rather, as suggestions of a direction it should go. As a matter of fact, I expect most of my requests to be resolved by the time you watch this video.
![]()
![]()
![]()
![]()
![]()
![]()
To make things more interesting, I will try to use the new “discovery” in Port to combine it with the whole life-cycle of resources. We’ll see how to combine it with Crossplane, Argo CD, GitHub Actions, and, probably, a few other tools. We’ll see how we can enable developers to manage anything, be it applications, databases, clusters, or anything else. We are about to build a whole platform, not only the console.
Buckle up!
Setup
Install GitHub CLI if you don’t have it already.
gh repo fork vfarcic/port-crds-demo --clone --remote
cd port-crds-demo
gh repo set-defaultSelect the fork as the default repository
gh repo view --webOpen
Actionsand click theI understand my workflows, go ahead and enable thembutton.
Open
Settings>Secrets and variables>Actionsand addRepository secretsnamedPORT_CLIENT_IDandPORT_CLIENT_SECRET. You can get those values from the Port UI.
Make sure that Docker is up-and-running. We’ll use it to create a KinD cluster.
Watch Nix for Everyone: Unleash Devbox for Simplified Development if you are not familiar with Devbox. Alternatively, you can skip Devbox and install all the tools listed in
devbox.jsonyourself.
devbox shell
chmod +x setup.sh
./setup.sh
source .envDiscover Data Models From API Schemas
Right now, I have a Kubernetes cluster with Crossplane and Argo CD running in it, and I have a GitHub repo with pretty much nothing in it. None of those tools are doing anything at the moment. They’re just sitting there.
I also have a Port account which is in a virgin state. It knows nothing about anything. It’s pretty dumb at the moment.
![]()
![]()
If I open the data models page, we can see that there is nothing there.
![]()
![]()
Similarly, self-serve actions like those to create, update, or delete instances based on the data model are nowhere to be seen.
As I said, my Port account is empty. It knows nothing. A newborn baby would know more about my resources and schemas than Port.
Now, I could start writing Json that defines data models or blueprints and, after that, turn my attention to actions. However, the fact that I could do that does not mean that I should do that. That would be a waste of my time since I already have schemas defined and accessible through API. I’m too old to waste little time I have left on recreating stuff that already exists.
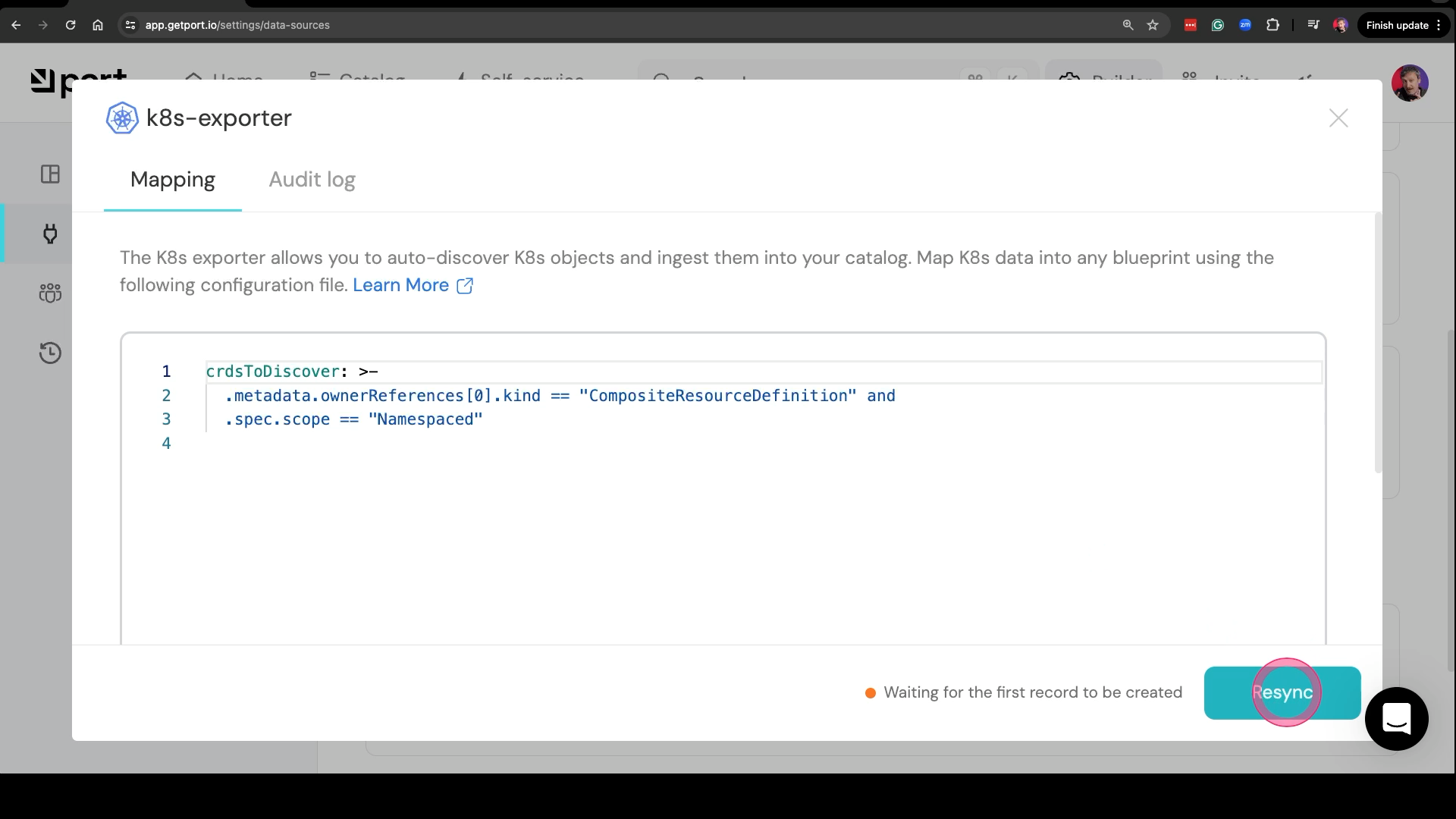
That’s where the new “discovery” feature comes in. Actually, I’m not sure what that feature is called. Maybe it’s called syncer. Doesn’t matter…
What does matter is that I can go to data sources and select k8s-exporter. It already contains the instruction to “discover” CRDs owned by Crossplane. You might have a different discovery criteria or you might want it to discover them all. In my case, all CRDs would mean hundreds of data models, so I’m limiting the discovery to only a few I made.
All that’s left is to click the Resync button and wait for a few moments.
While waiting, I can start with my complaints or, to be more precise, requests to Port folks.
Message to Port: Do NOT ask me to resync. You should resync whenever you detect changes to my CRDs. Clicking buttons is, for me, similar to going to a dentist. No one enjoys going to a dentist so visits are limited to emergency situations. Similarly, if I already instructed Port what the discovery criteria is, there is no good reason for me to keep clicking that button every time one of the selected CRDs change.
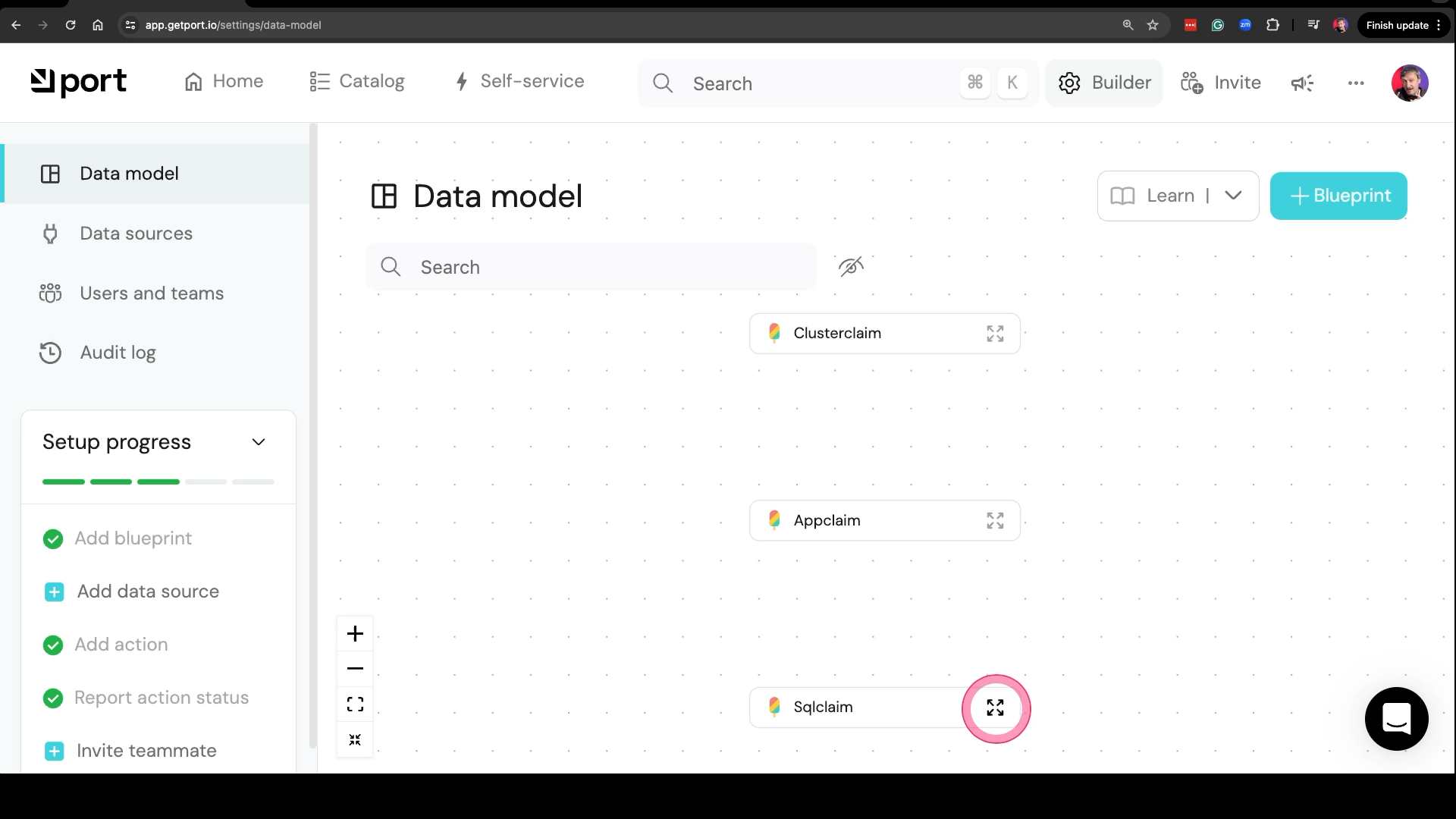
Now we can go back to the data models screen and, lo and behold, three were created for us.
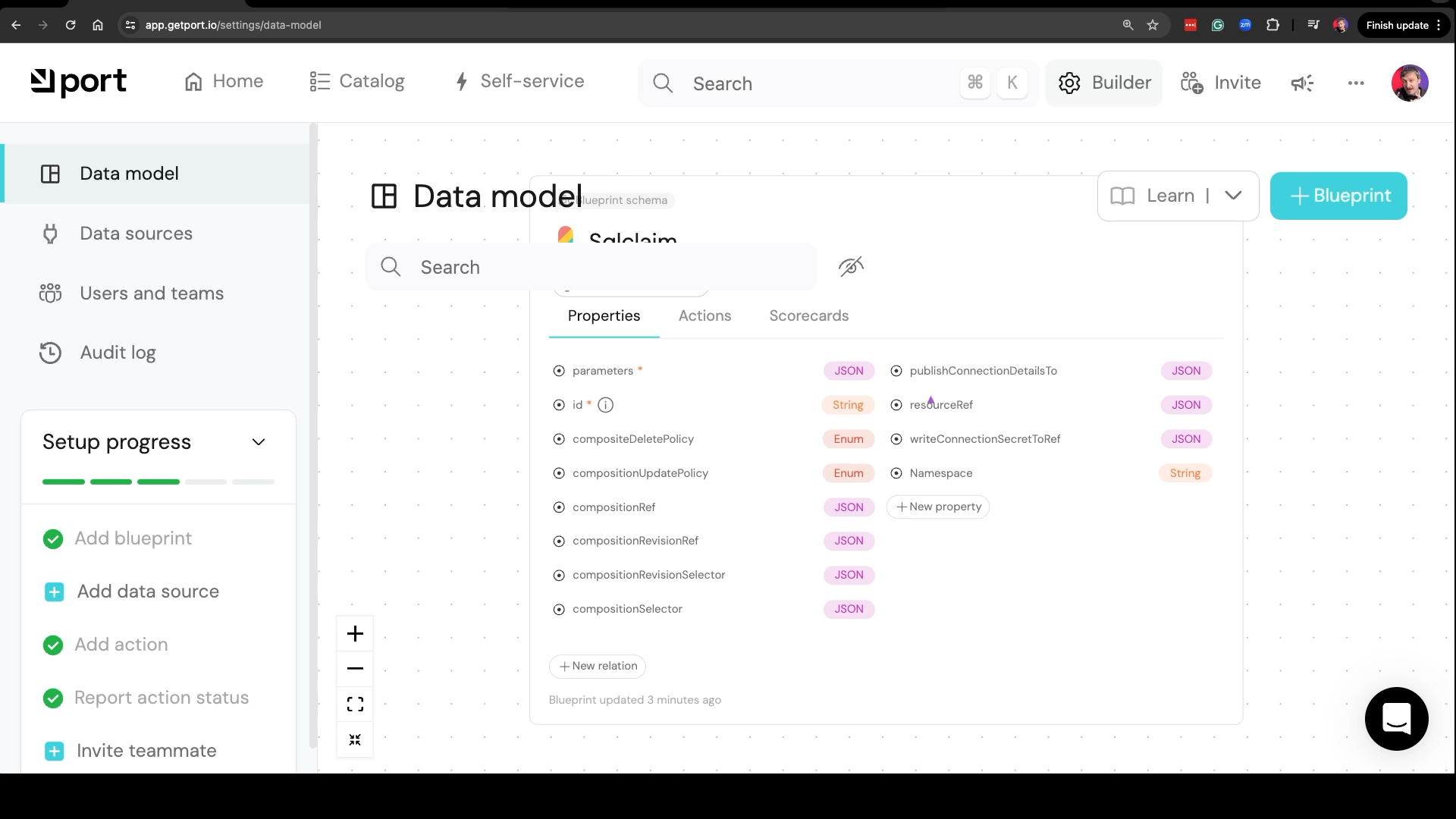
If we open, for example, Sqlclaim, we can see that Kubernetes API schema was discovered and translated to Port’s data model. I did not have to do anything, and that makes me happy. That’s awesome, but also leads me to the second feature request.
Message to Port: Do not convert all children fields to Json blob. Extract all the fields from a schema and store them separately. Otherwise, I have no idea, what is the parameters field. It could contain an unknown number of sub-fields.
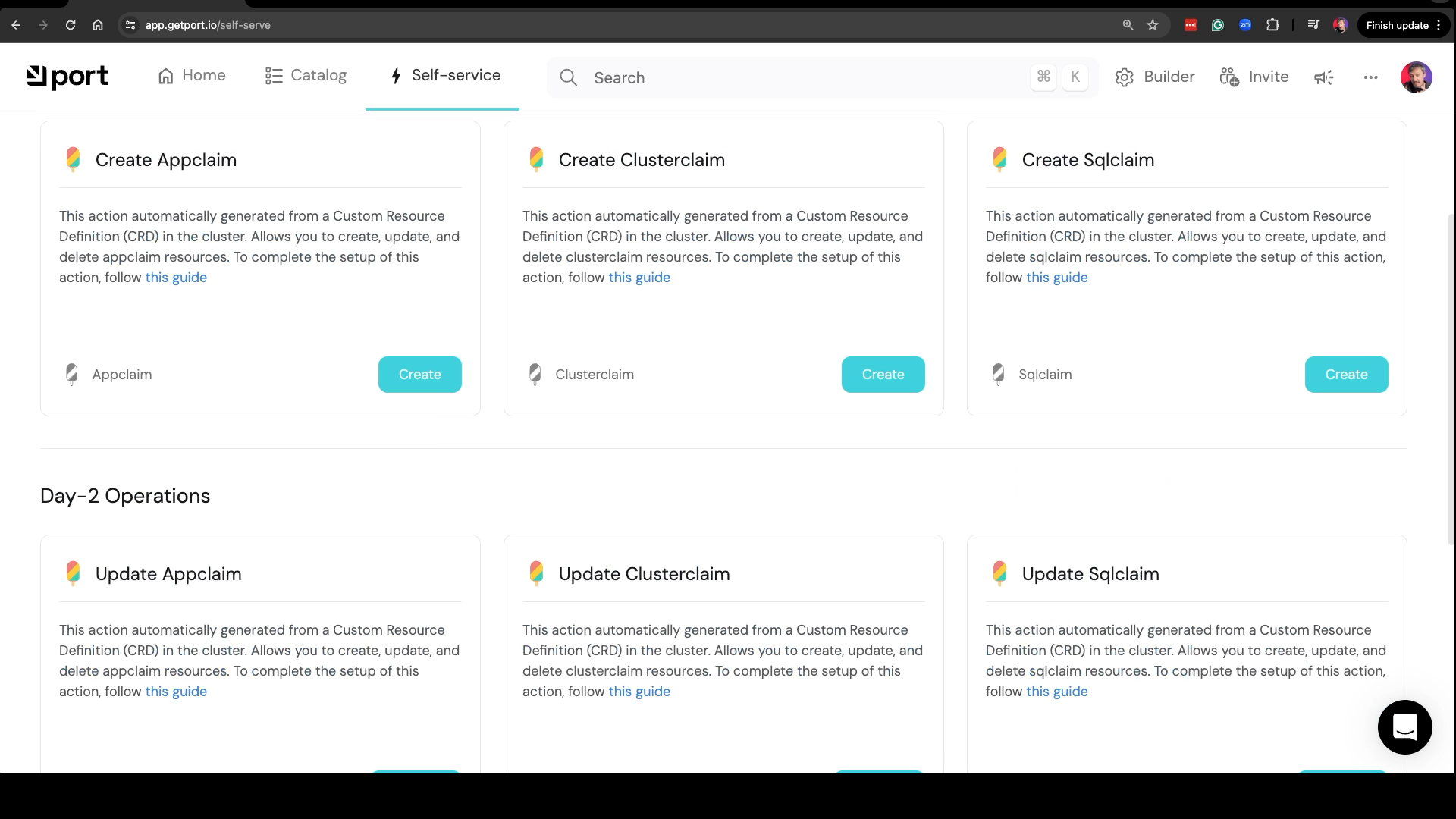
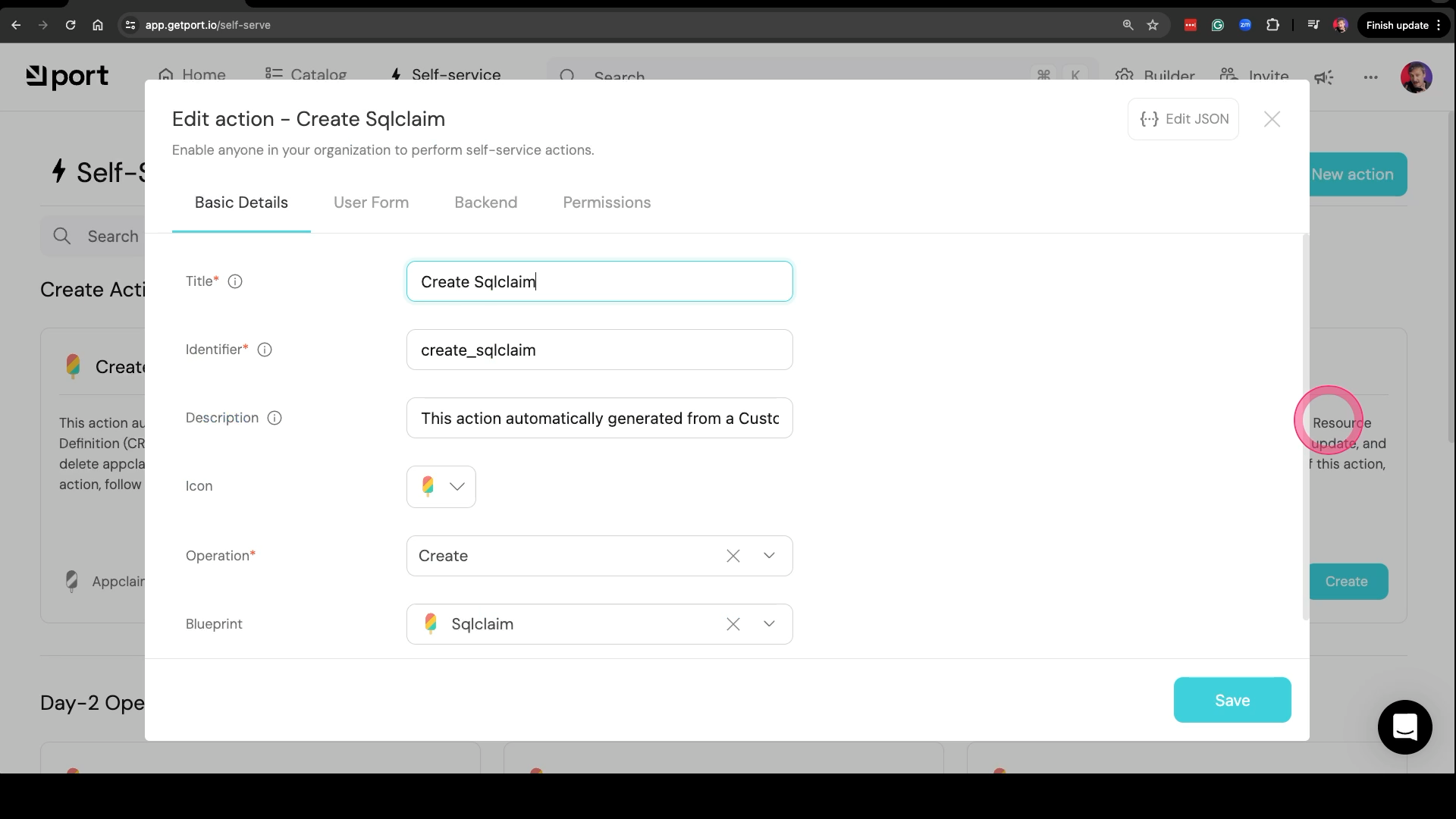
If we switch to the Self-service page, we get an even better surprise. It converted those three data models into actions. We can Create, Update, or Delete resources. If creation of data models is awesome, actions are amazing.
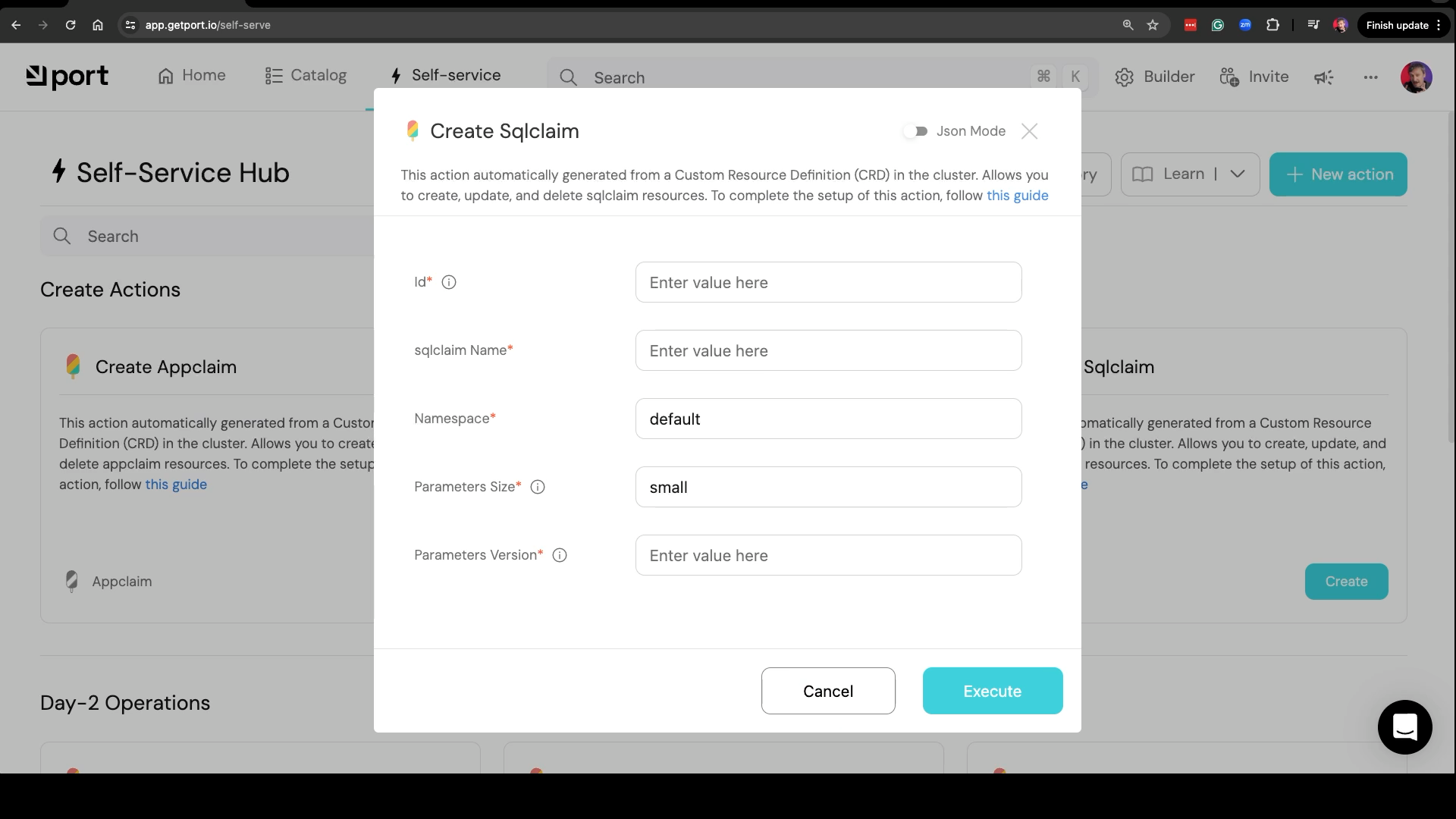
If, for example, we would like to create a database, we can simply click the Create button, fill in a few fields, and click the Execute button. However, that’s not what we’ll do. A field is missing, so we should add it first.
We can do that by selecting the Edit option in Create Sqlclaim.
From here on, we could edit using the graphical user interface but, given that too many colors scare me, we’ll switch to the Json view by clicking the Edit JSON button.
That Json contains, among other things, all the fields discovered from the CRD, thus proving that Port can do it, and making it even more confusing that the same did not happen in the data model (my first feature request). Some of those fields are visible, while others are not. Port chose to put only required fields as visible, and all the others as hidden. That makes a lot of sense when working with third-party CRDs like CPNG or Knative. They contain more fields than what we might need. However, the CRDs we’re using today are not third-party. They were created by me through Crossplane compositions. If I did not think that people in my organization need some of those fields, I would not include them in the CRD. Hence, for our own CRDs, it would make much more sense to have them all as visible by default, with the option to hide some of them. That leads me to the third-feature request.
Message to Port: I know you will read this post. Please add the option to have all fields visible by default when specifying syncer. You’re making me waste my time by having to enable them for no good reason.
Going back to the task at hand… The field that is required for SQLClaims to work, yet not visible out of the box is compositionRef__name so we’ll change visible to true, and click the Save button.
The output (truncated for brevity).
{
"identifier": "create_sqlclaim",
...
"trigger": {
"type": "self-service",
"operation": "CREATE",
"userInputs": {
"properties": {
...
"compositionRef__name": {
"type": "string",
"visible": true
},
...There’s one more thing that we can do to make the user experience much better. We should change the type of some of the fields to “select” by selecting Edit again followed by User Form. I realized that not everyone has problems with pretty colors, so, this time, I’ll stay away from Json.
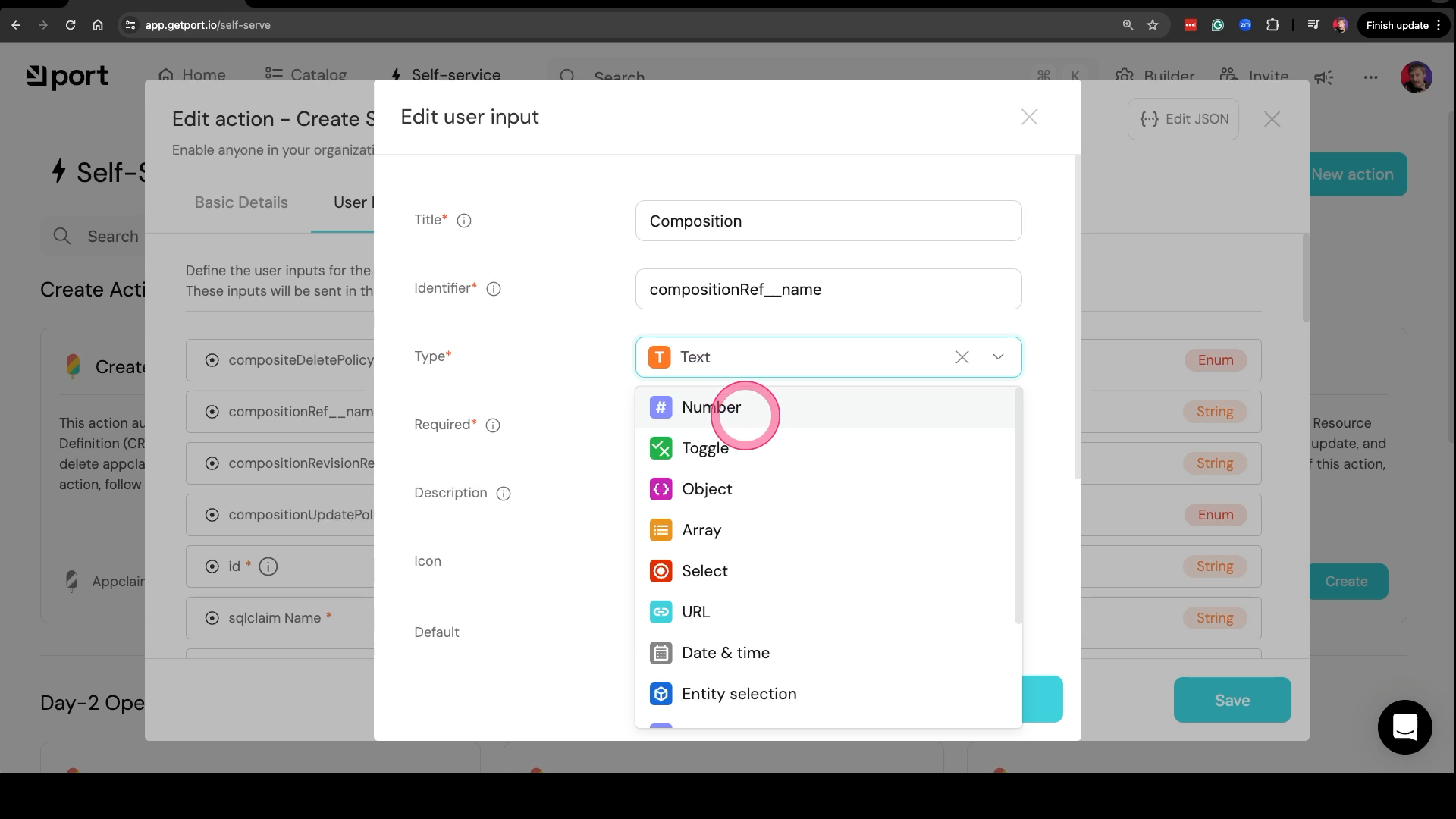
We’ll select Edit property of compositionRef__name, set the Title to Composition, change the Type to Select, add options aws-postgresql, azure-postgresql, and google-postgresql, and click the Save button.
We’ll see the effect of that soon. For now, we need to do the same for parameters__size. Set the Title to Size, change the Type to Select, add options small, medium, and large, and click the Save button.
We’re almost done. The only thing missing for us to get a fully operational developer platform, is to define actions. Port already created them, but we need to change a few things.
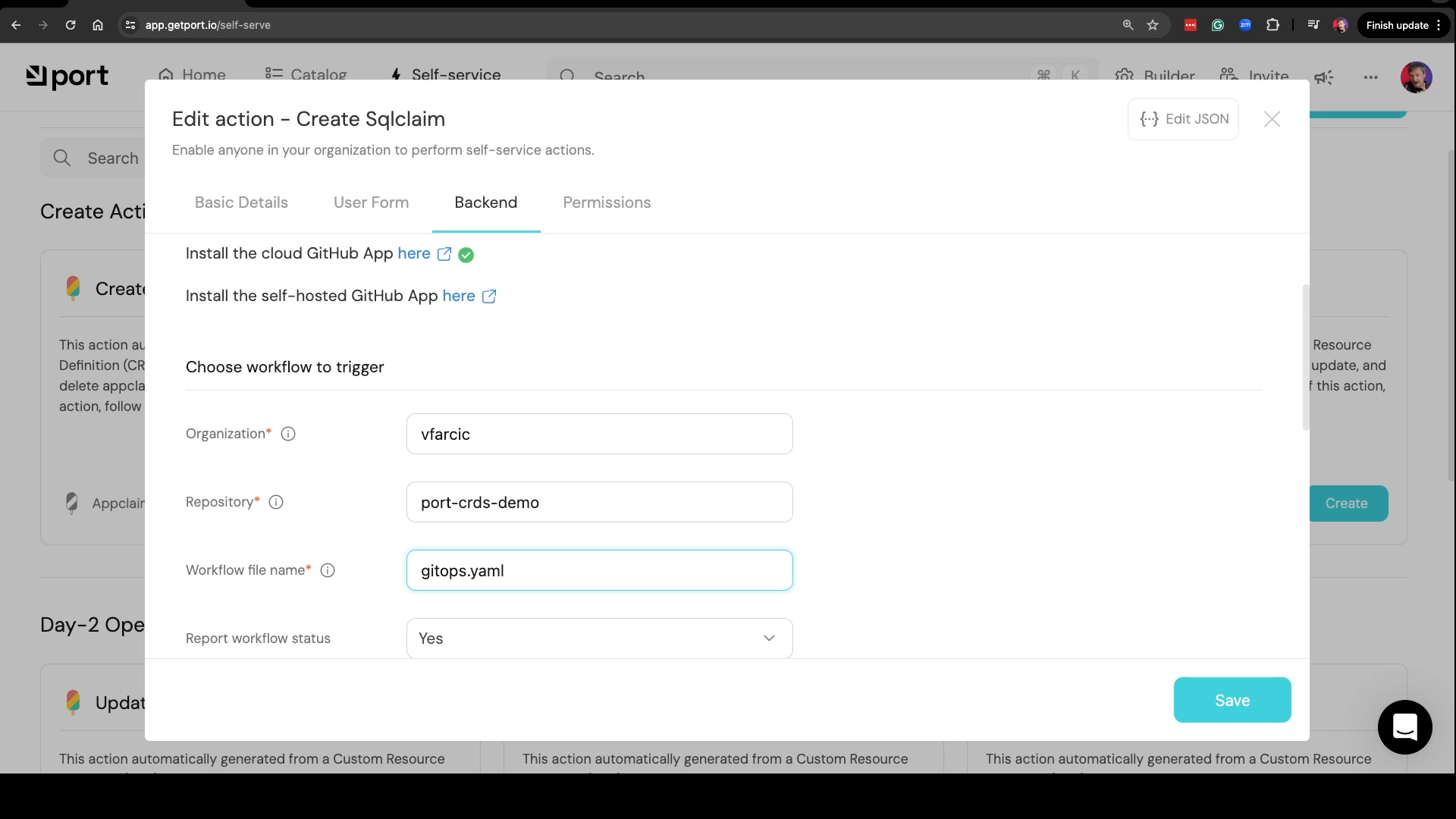
Select the Backend button from the top menu, type the Organization, set Repository to port-crds-demo, set Workflow file name to gitops.yaml, and click the Save field.
From now on, whenever we choose to create a database, Port will execute the specified GitHub Action and pass it all the information it has. That’s an awesome feeling that is about to be crashed by another annoyance.
We need to do the same for Update Sqlclaim and Delete Sqlclaim.
So, Edit Update Sqlclaim, click the Backend button from the top menu, type the Organization, set Repository to port-crds-demo, set Workflow file name to gitops.yaml, and click the Save field.
Since doing the same thing twice might not be annoying enough, let’s do it one more time.
Edit Delete Sqlclaim, click the Backend button from the top menu, type the Organization, set Repository to port-crds-demo, set Workflow file name to gitops.yaml, and click the Save field.
As you can guess, another feature request is coming up.
Message to Port: It’s pointless to do the same thing over and over again. There should be an option to say “the same organization, repository, and workflow file name applies to all the selected actions.
Now we’re getting to the part of the video that might cause developers to have a minor orgasm.
Create Service Instances
Let’s say that a developer asks you to create a database. What should be your response? “Yes sir. Right away sir.” An alternative would be to say “Stop bothering me! Do it yourself.”.
I prefer the latter. Calling someone “sir” is not something I’m inclined to do.
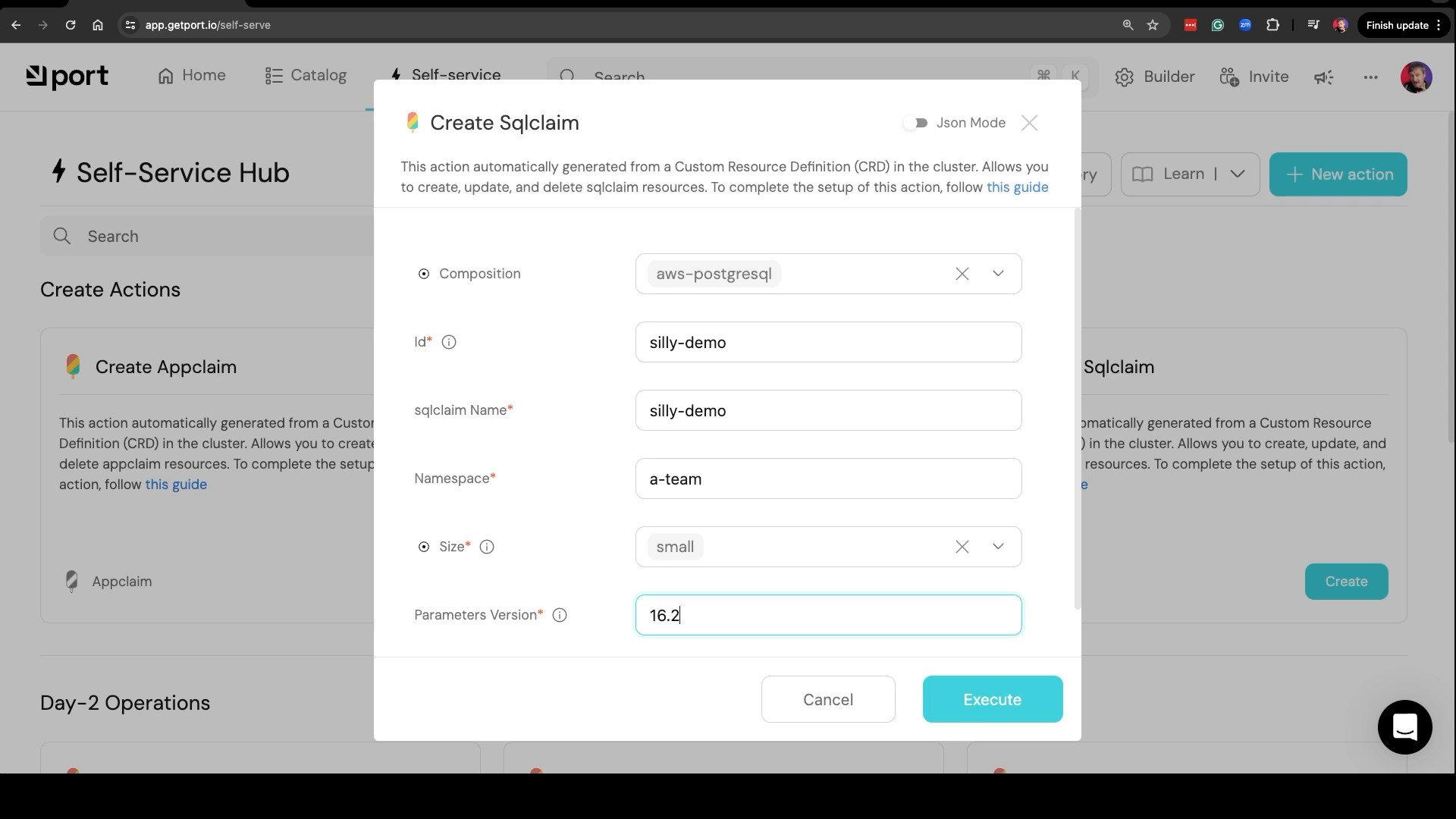
That developer can simply click the Create button in Create Sqlclaim, pick a composition that will create that database in AWS, Google Cloud, or Azure, use silly-demo as both the id and the sqlclaim Name, set a-team as the Namespace, specify the version of the database (set 15 if using Google Cloud, 16.2 if using AWS, 11 if using Azure, or any value if not using any hyperscaler), and click the Execute button. That’s it. That’s all there is to it. The developer had a great experience all thanks to you creating a Database-as-a-Service solution.
Nevertheless, here comes yet another feature request.
Message to Port: Namespaces could be imported as a blueprint and available as a select list. We can do that today, but it’s tedious since it requires unnecessary extra steps. Port should know that any namespaced CRD in Kubernetes needs Namespaces and convert that text field into a selection which we might modify later.
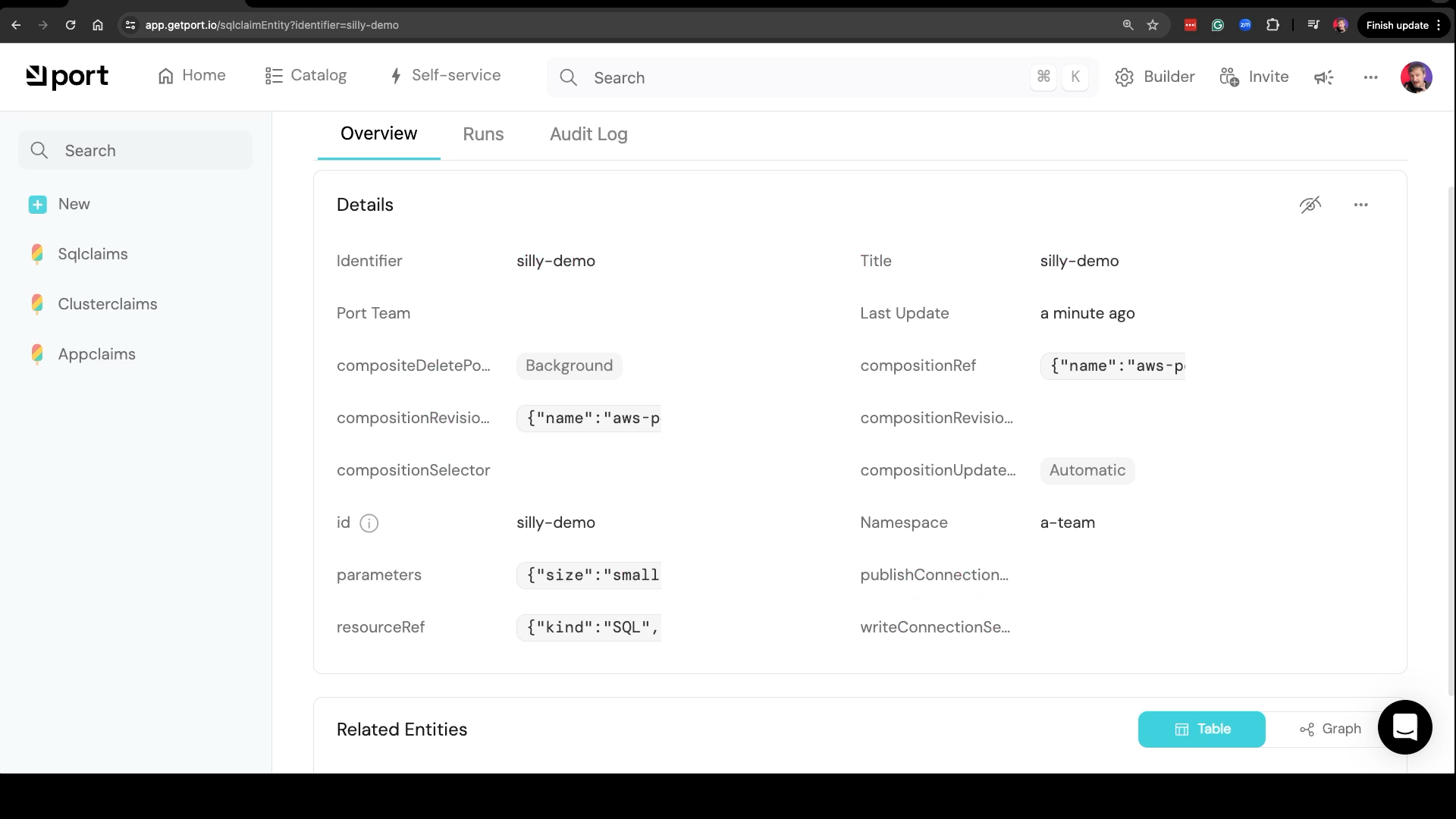
That’s not all. That developer could now go to the catalog, and open the list of sqlclaims. The silly-demo should be there and he, or she, could see all the details. That’s awesome, and effortless, yet, there is still room for improvement.
Message to Port: Do not show Json. It’s silly in this context. Convert it into keys and values instead. Show them one below another. Users of the platform should not have to deal with internal complications related to Port’s data models.
Nice thing is that we can hide the fields that might not be relevant. I’ll leave you to discover that part by yourself since I just got distracted by yet another feature request.
Message to Port: Where are statuses and events? Seeing the same data as those users specified is great, but what really matters are statuses and events. How can that developer know whether the database is working? If it’s not working, how will they find out what’s wrong with it? We’re running blind here.
We saw that it is relatively easy for service providers to enable their services to be consumed through a graphical user interface as well as developers to consume those services. When we created a Sqlclaim, the end result is that quite a few resources were created automagically in one of the “big three” hyperscalers. Without further explaination what happened could be considered magic. But, since I have no intention to act as shaman, we should probably discuss what happened behind the scenes.
What Happened?
Here’s what happened.
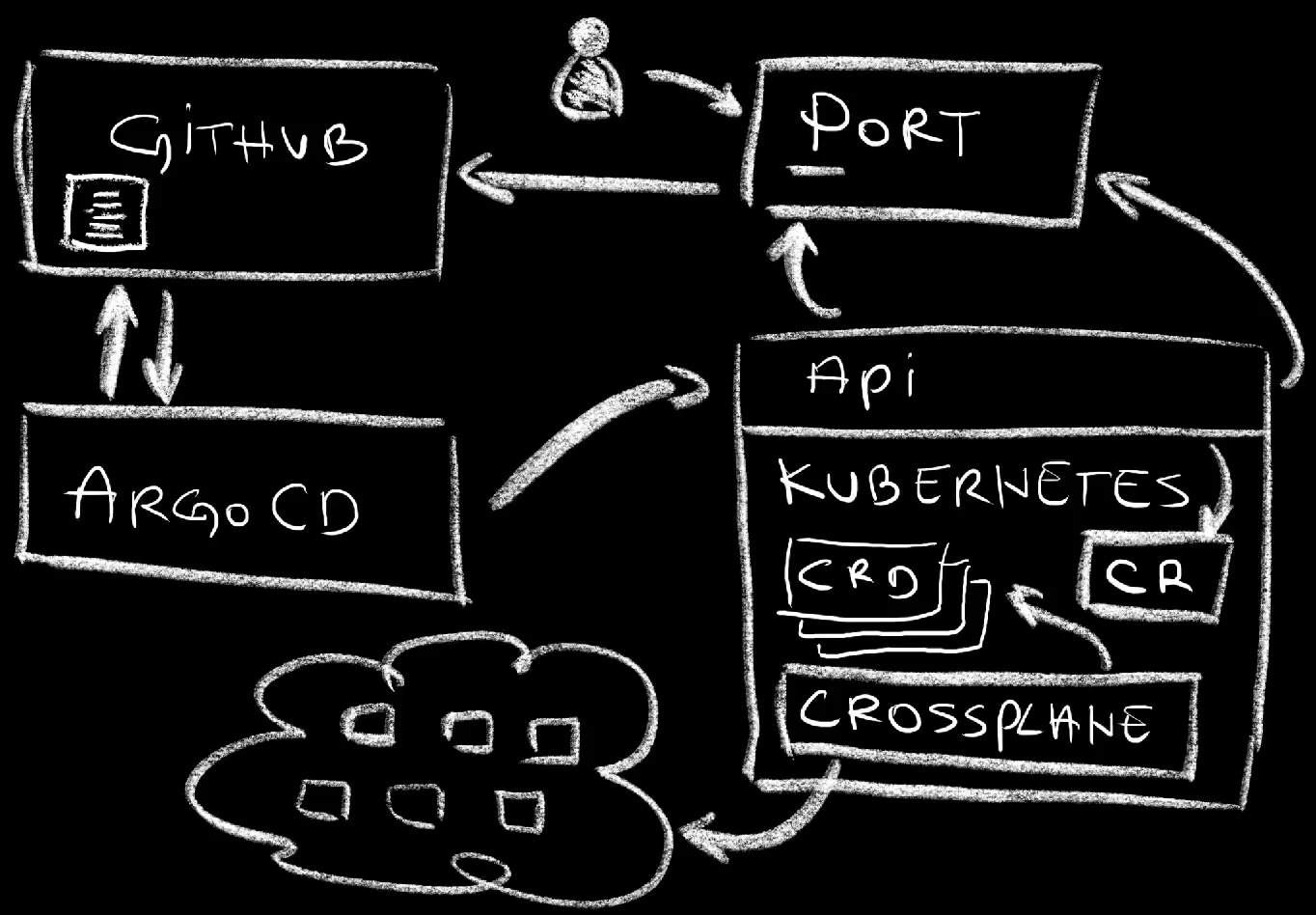
Port retrieved information about all the API endpoints that match the specified criteria. Since that API is Kubernetes, those endpoints are Custom Resource Definitions. Once Port got the information it needs, it converted it into its own internal format and generated data models or blue-prints and self-service actions.
We had to make a few changes here and there but, other than those, everything was done automatically without any human intervention.
Those CRDs were created by Crossplane Compositions which enable us to create services. In this cases, there were three such services, one that manages applications, one for clusters, and one for databases.
When the developer triggered one of those self-service actions, a request was sent to GitHub Actions to start a workflow which created a manifest in the repository.
Argo CD, in turn, was watching that repository and as soon as a Sqlclaim manifest was pushed it synchronized it into the cluster.
Since the resource defined in that manifest is Crossplane’s claim, Crossplane expanded it into a bunch of managed resources that created some resources in that same cluster and others in whichever hyperscaler developer chose.
At the same time, Port agent running inside that cluster noticed creation of the claim and pushed the information which, eventually we observed in the catalog.
Here’s the best part though. It took me more time to explain what happened than to set it up.
Now that we saw what happened, let’s discuss how it happened.
How Did It Happen?
The first thing I did was to create a Kubernetes cluster that will act as a control plane. Inside that cluster, I installed Crossplane, Argo CD, and Port Agent.
From there on, I installed Crossplane providers that created custom resource definitions and controllers like, for example, those that can be used to manage resources in AWS.
We can see those by listing all CRDs.
kubectl get crdsThe output is as follows (truncated for brevity).
NAME CREATED AT
accesskeys.iam.aws.upbound.io 2024-05-22T23:41:17Z
accountaliases.iam.aws.upbound.io 2024-05-22T23:41:17Z
accountpasswordpolicies.iam.aws.upbound.io 2024-05-22T23:41:17Z
activedirectoryadministrators.dbforpostgresql.azure.upbound.io 2024-05-22T23:41:09Z
addons.eks.aws.upbound.io 2024-05-22T23:41:14Z
amicopies.ec2.aws.upbound.io 2024-05-22T23:41:20Z
...There are a couple of hundred different CRDs over there.
TODO: Thumbnails: bBpE0rfE-JM, o53_7vuWjw4
*If you are not familiar with Crossplane and providers, please watch Getting Started with Crossplane: A Glimpse Into the Future and Crossplane Providers and Managed Resources
Then I created Compositions that manage Applications, Clusters, and Databases in AWS, Azure, and Google Cloud. Those Compositions also created Custom Resource Definitions.
We can see them by filtering the list of crds with devops.
kubectl get crds | grep devopsThe output is as follows.
appclaims.devopstoolkitseries.com 2024-05-22T23:40:15Z
apps.devopstoolkitseries.com 2024-05-22T23:40:14Z
clusterclaims.devopstoolkitseries.com 2024-05-22T23:41:55Z
compositeclusters.devopstoolkitseries.com 2024-05-22T23:41:55Z
sqlclaims.devopstoolkitseries.com 2024-05-22T23:41:43Z
sqls.devopstoolkitseries.com 2024-05-22T23:41:43ZSince I don’t want to convert this into a never ending story I won’t explain how to create Compositions, just as I won’t explain in depth what’s coming next. I already did that in various videos, many of them being related to Crossplane. Watch Crossplane Compositions if you’re not familiar with Crossplane Compositions.
The important thing to note about CRDs is that they are API endpoints and their schema can be discovered.
We can do that discovery using kubectl explain command.
kubectl explain appclaims.devopstoolkitseries.com --recursiveThe output is as follows (truncated for brevity).
GROUP: devopstoolkitseries.com
KIND: AppClaim
VERSION: v1alpha1
...
FIELDS:
...
spec <Object> -required-
compositeDeletePolicy <string>
compositionRef <Object>
name <string> -required-
compositionRevisionRef <Object>
name <string> -required-
compositionRevisionSelector <Object>
matchLabels <map[string]string> -required-
compositionSelector <Object>
matchLabels <map[string]string> -required-
compositionUpdatePolicy <string>
id <string> -required-
parameters <Object> -required-
db <Object>
secret <string>
host <string>
image <string> -required-
kubernetesProviderConfigName <string>
namespace <string>
port <integer>
...What matters, for this story, is that Port could discover the schema, and that’s what it did. That same schema, together with a few others, was imported into Port and translated to its own data models (blueprints) and actions.
When we triggered the action to create a Sqlclaim, Port sent a request that executed a GitHub Actions Workflow.
Here’s that workflow definition.
cat .github/workflows/gitops.yamlThe output is as follows.
name: Sync control plane
permissions:
contents: write
on:
workflow_dispatch:
inputs:
operation:
required: true
description: "Delete, Update or create"
type: string
triggeringUser:
required: true
description: "The email of the triggering user"
type: string
runId:
required: true
description: "Port's Run ID"
type: string
manifest:
required: true
description: "The K8s manifest generated by Port"
type: string
folder:
required: true
description: Folder where the resource will be stored
default: "./apps"
type: string
jobs:
push:
runs-on: ubuntu-latest
steps:
- name: checkout
uses: actions/checkout@v2
- uses: mikefarah/yq@v4.44.1
- uses: port-labs/port-github-action@v1
with:
clientId: ${{ secrets.PORT_CLIENT_ID }}
clientSecret: ${{ secrets.PORT_CLIENT_SECRET }}
operation: PATCH_RUN
runId: ${{inputs.runId}}
icon: GithubActions
logMessage: "${{ inputs.operation }} manifest ${{ env.PATH }}..."
- name: manifest
run: |
echo '${{ inputs.manifest }}' | yq -p json -o yaml | tee tmp.yaml
kind=$(yq .kind tmp.yaml)
name=$(yq .metadata.name tmp.yaml)
namespace=$(yq .metadata.namespace tmp.yaml)
path=${{ inputs.folder }}/$namespace-$kind-$name.yaml
if [ "${{ inputs.operation }}" = "DELETE" ]; then
rm -f $path
rm -f tmp.yaml
else
mv tmp.yaml $path
fi
- name: Push
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: |
git config user.name "GitHub Action"
git config user.email "github-actions[bot]@users.noreply.github.com"
git add .
git commit -m "chore: ${{ inputs.operation }} resource by ${{ inputs.triggeringUser }}"
git push The inputs fields are probably self explanatory. Port sends us the operation which could be CREATE, UPDATE, or DELETE. Then there is the triggeringUser, and the Port’s runId. The manifest contains the manifest created through Action’s form while folder represents the directory where the manifest should be stored. It’s set to be ./apps by default.
The steps in the Job are relatively simple. We’re doing code checkout and installing yq. port-github-action can be used to propagate a logMessage back to Port UI.
The action is happening in the manifest step that converts Port’s JSON into YAML and extracts resource kind, name, and namespace from it. We’re using it to generate a unique path of the manifest. Finally, if the operation is to DELETE a resource, the file is removed. Otherwise, the temporary YAML manifest (tmp.yaml) is moved to the path.
Finally, the last step pushes the changes back to the repo.
It’s a relatively simple workflow which is similar to what we would normally do without Port. Generate the manifest and push it back to the repo so that Argo CD can synchronize it with the cluster.
I’m assuming that you’re familiar with GitHub Actions. If not, please watch Github Actions Review And Tutorial. Also, please note that it does not have to be GitHub Actions. Port is flexible and can send requests to almost anything.
We can confirm that Port indeed triggered that workflow which pushed a manifest to the repo by pulling the latest version…
git pull…and listing all the files in the apps directory.
ls -1 apps/The output is as follows.
a-team-SQLClaim-silly-demo.yaml
emptyThe a-team-SQLClaim-silly-demo.yaml file was indeed created and we can see what’s in it.
cat apps/a-team-SQLClaim-silly-demo.yamlThe output is as follows.
apiVersion: devopstoolkitseries.com/v1alpha1
kind: SQLClaim
metadata:
name: silly-demo
namespace: a-team
spec:
compositionRef:
name: aws-postgresql
id: silly-demo
parameters:
size: small
version: "16.2"That is SQLClaim generated based on the input we provided by filling in the form in Port.
As I already mentioned, once the manifest was pushed to the repo, Argo CD detected the change and synchronized it into the control plane cluster. We can confirm that by opening Argo CD UI.
echo "http://argocd.127.0.0.1.nip.io"Open the URL in a browser. Use
adminas the username andadmin123as the password. Show thea-teamApplication.
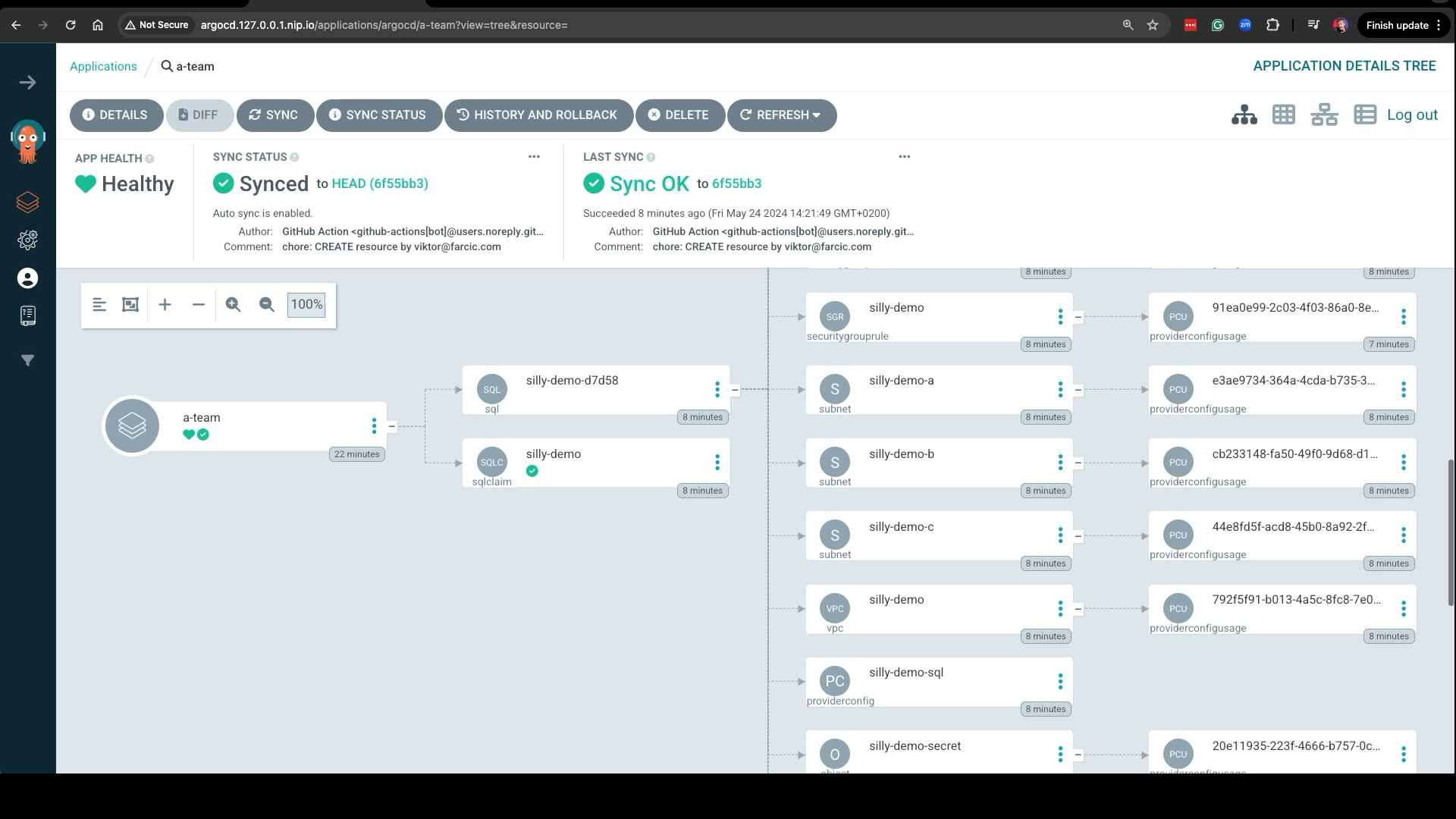
The silly-demo SQLClaim was indeed created.
I’m sure you’re familiar with Argo CD. If you’re not, there’s a whole Argo CD playlist.
Since the resource that was synced into the control plane cluster is a claim of a Crossplane Composition, it expanded into all the resources required to run the database in a hyperscaler.
Apart from seeing those resources from Argo CD UI, we can also confirm that’s indeed what happened through the crossplane trace command.
crossplane beta trace sqlclaim silly-demo --namespace a-teamThe output is as follows.
NAME SYNCED READY STATUS
SQLClaim/silly-demo (a-team) True True Available
└─ SQL/silly-demo-q4qvx True True Available
├─ InternetGateway/silly-demo True True Available
├─ MainRouteTableAssociation/silly-demo True True Available
├─ RouteTableAssociation/silly-demo-1a True True Available
├─ RouteTableAssociation/silly-demo-1b True True Available
├─ RouteTableAssociation/silly-demo-1c True True Available
├─ RouteTable/silly-demo True True Available
├─ Route/silly-demo True True Available
├─ SecurityGroupRule/silly-demo True True Available
├─ SecurityGroup/silly-demo True True Available
├─ Subnet/silly-demo-a True True Available
├─ Subnet/silly-demo-b True True Available
├─ Subnet/silly-demo-c True True Available
├─ VPC/silly-demo True True Available
├─ ProviderConfig/silly-demo-sql - -
├─ ProviderConfig/silly-demo-sql - -
├─ Object/silly-demo-secret True True Available
├─ ProviderConfig/silly-demo - -
├─ SubnetGroup/silly-demo True True Available
└─ Instance/silly-demo True True AvailableSince I chose AWS, we got InternetGateway, MainRouteTableAssociation, a few RouteTableAssociations, and quite a few other resources, including the RDS Instance itself. All those resources are managed by Crossplane and are currently running in AWS.
Finally, developers do not necessarily need to know or worry about any of that. For them, the only thing that matters is that they can create instances of services provided to them and that they can see the details from Port’s catalog.
So far, we explored how to create service instances and we might want to check out how to update and delete them as well.
Update and Delete Service Instances
Updating and deleting service instances follows the same pattern.
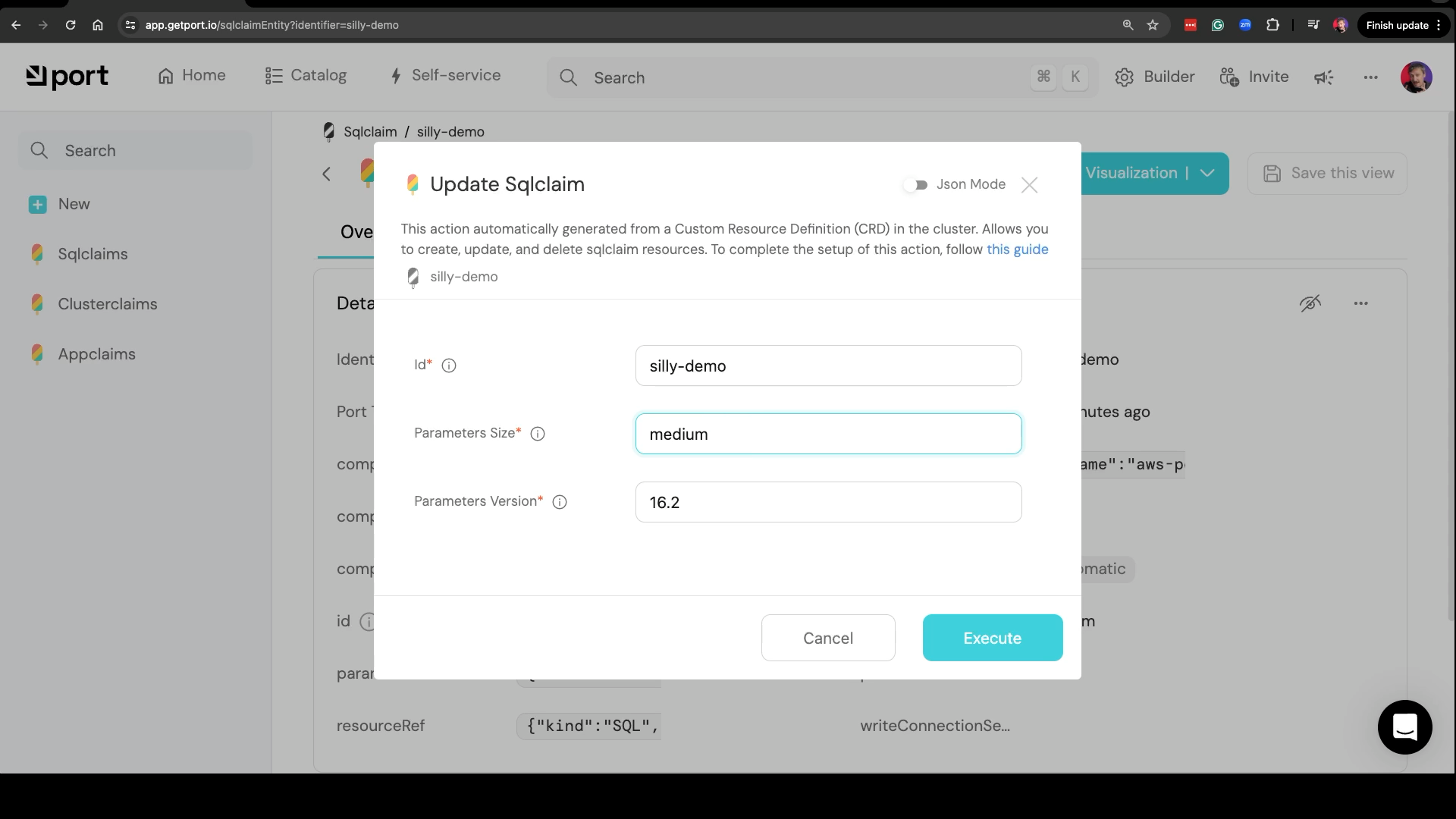
We can, for example choose to Update Sqlclaim, change the Parameters Size to medium, and click the Execute button.
From here on, the process follows the same pattern. Port triggered GitHub Actions workflow which updated the manifest and pushed it back to the repo. Argo CD synced it into the control plane cluster and Crossplane created, updated, or deleted whichever resources needed a change.
Normally, I would not bother showing you that’s what really happened since you probably trust me by now. Nevertheless, I do need to pull the latest code…
git pull…and output the manifest.
cat apps/a-team-SQLClaim-silly-demo.yamlThe output is as follows.
apiVersion: devopstoolkitseries.com/v1alpha1
kind: SQLClaim
metadata:
name: silly-demo
namespace: a-team
spec:
compositeDeletePolicy: Background
compositionRef:
name: aws-postgresql
compositionRevisionRef:
name: aws-postgresql-28b1771
compositionUpdatePolicy: Automatic
id: silly-demo
parameters:
size: medium
version: "16.2"
resourceRef:
apiVersion: devopstoolkitseries.com/v1alpha1
kind: SQL
name: silly-demo-q4qvxThis is a good news bad news type of a situation.
On the bright side, Port correctly identified not only what we wanted to change (size: medium) but also the previous state of that resource. For example, it figured out that the namespace is a-team without us telling it that.
The bad news is that it pulled some information from the cluster that should not be in the manifest. For example, the compositionRevisionRef is not something we should specify but a value autogenerated by Crossplane. That leads me to yet another feature request.
Message to Port: do no add values that were not specified in any of the forms, unless explicitly set by whomever is designing actions. Instead, compare the actual resource with whatever is stored in Port or in Git or wherever else you might find the desired state.
That was, hopefully, the last feature request, at least for today.
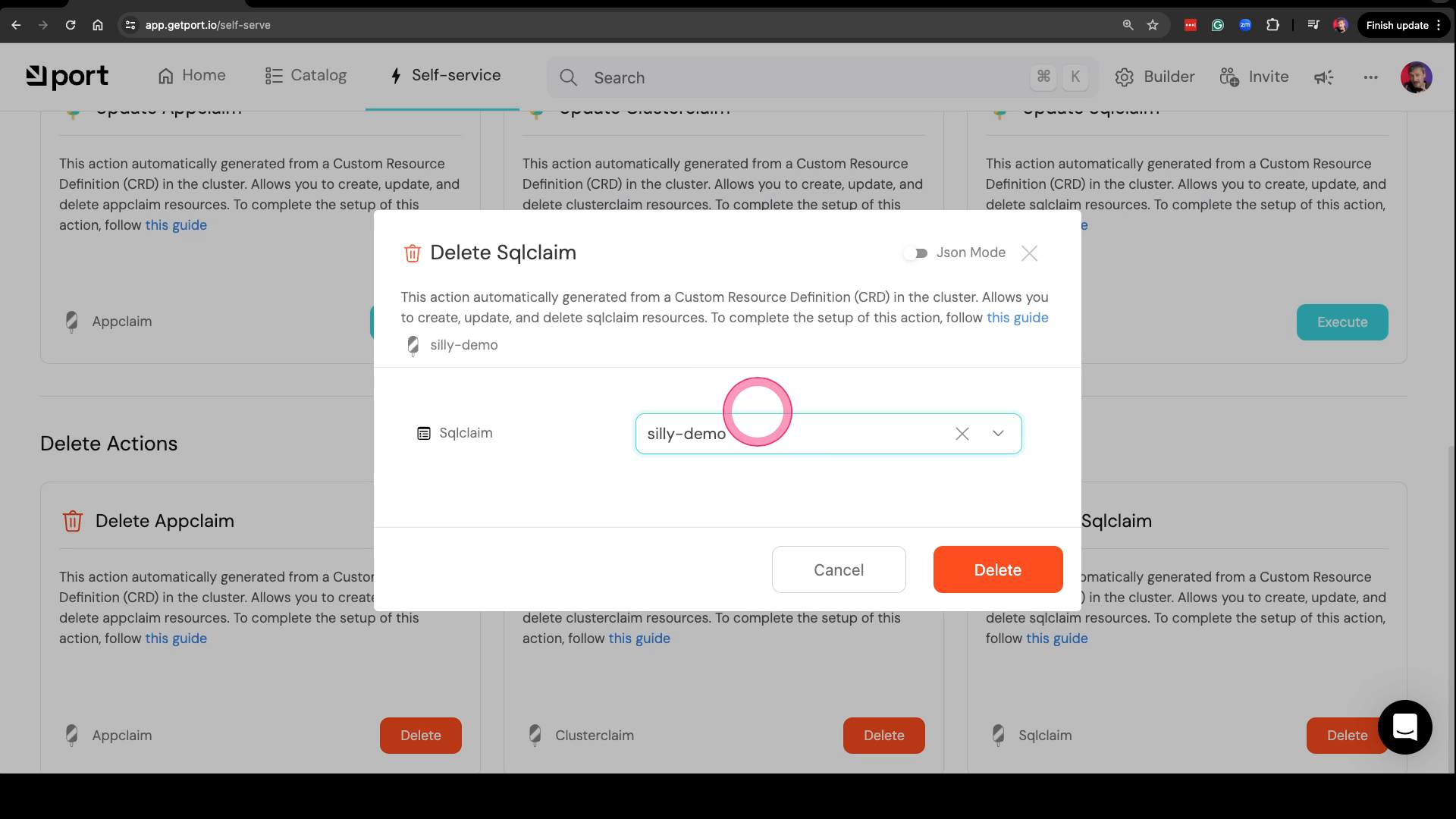
Finally, we can just as well close the circle by opening the self-serving page, clicking the Delete button in Delete Sqlclaim, selecting silly-demo, and clicking the Delete button.
That’s it. The database and everything around it will be gone in a few moments. It will be deleted from Port and from the repo and from the control plane and from AWS and from wherever else it might be. It’s gone forever, unless you go back through the repo history.
Destroy
chmod +x destroy.sh
./destroy.sh